Reproducibledata pipelines solved
Kedro is a toolbox for production-ready data pipelines.

Why Kedro?
Kedro's Key Concepts Explained →
Features
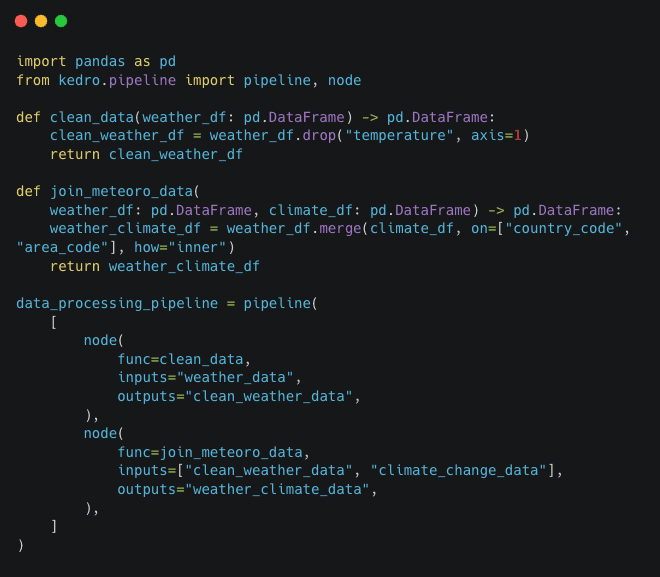
Pipeline Visualisation
Kedro-Viz is a blueprint of your data and machine-learning workflows. It provides data lineage, surfaces detailed pipeline execution information such as execution time, node status, dataset statistics, and makes it easier to collaborate with business stakeholders.
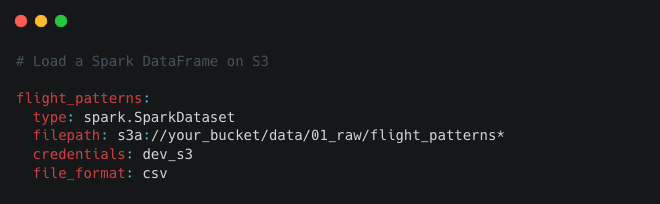
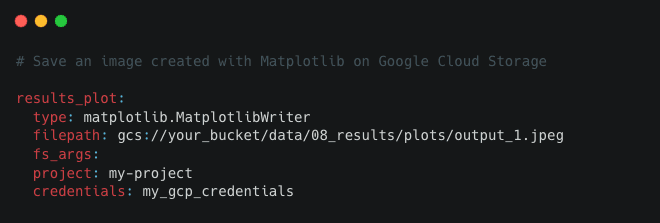
Data Catalog
A series of lightweight data connectors used to save and load data across many different file formats and file systems. The Data Catalog supports S3, GCP, Azure, sFTP, DBFS, and local filesystems. Supported file formats include Pandas, Spark, Dask, NetworkX, Pickle, Plotly, Matplotlib, and many more. The Data Catalog also includes data and model snapshots for file-based systems.
Integrations
Amazon SageMaker, Apache Airflow, Apache Spark, Azure ML, Dask, Databricks, Docker, fsspec, Jupyter Notebook, Kubeflow, Matplotlib, MLflow, Plotly, Pandas, VertexAI, and more.

Project Template
You can standardise how configuration, source code, tests, documentation, and notebooks are organised with an adaptable, easy-to-use project template. Create your cookie cutter project templates with Starters.

Dedicated IDE support
The extension integrates Kedro projects with Visual Studio Code, providing features like enhanced code navigation and autocompletion for seamless development.

FAQs
You can find the Kedro community on Slack.
We also maintain a list of extensions, plugins, articles, podcasts, talks, and Kedro showcase projects in the awesome-kedro repository.
What is Kedro?
Kedro is an open-source Python framework hosted by the Linux Foundation (LF AI & Data). Kedro uses software engineering best practices to help you build production-ready data engineering and data science code.
What does Kedro do?
Is Kedro an orchestrator?
I'm a Data Scientist. Why should I use Kedro?
I'm a Machine-Learning Engineer/Data Engineer. Why should I be interested in Kedro?
I'm a Product Lead, and my team wants to use Kedro. Why?
What's Kedro's origin story?
How can I find out more about Kedro?















Case studies
Kedro in production at


Testimonials

Eduardo Ohe, Principal Data Engineer
Ready to start?
Kedro is an open-source project. Go ahead and install it with pip or conda:
pip install kedro
or
conda install -c conda-forge kedro
For more details, see the set up documentation or watch the video.
