
In Kedro, runners are the execution mechanism for data science and machine learning pipelines. The default behaviour of all of Kedro’s built-in runners is to halt pipeline execution if an error occurs that is significant enough to cause any of the nodes to fail, as shown in the following diagram:
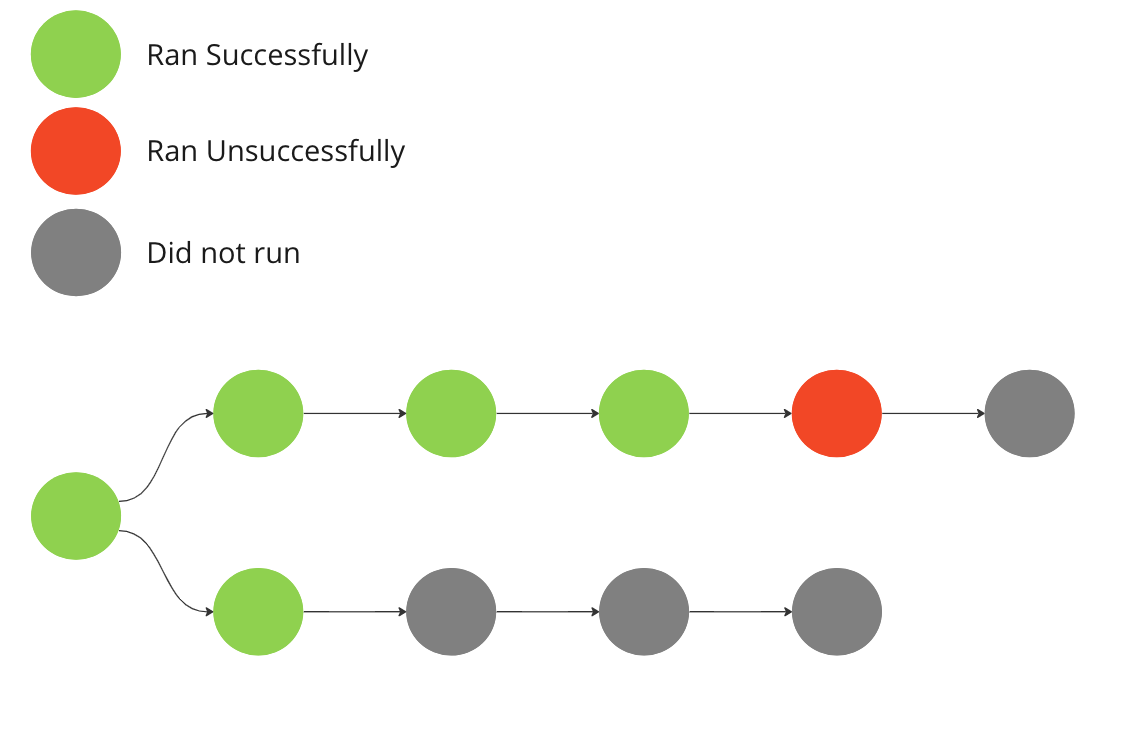
In the diagram, the entire run aborts when it encounters a node that it cannot run, terminating all other sections or branches of the pipeline, even those that it could have run.
The custom runner described in this article was specifically developed for a top player in the mining industry that uses Kedro to construct data pipelines for BI dashboards essential for operational excellence.
The client’s pipeline is designed to be resilient towards node failures. Certain nodes operate independently of each other, and especially during the development and exploration stages, the failure of a single node does not necessitate the termination of the entire Kedro run. The desired behaviour is as shown below:
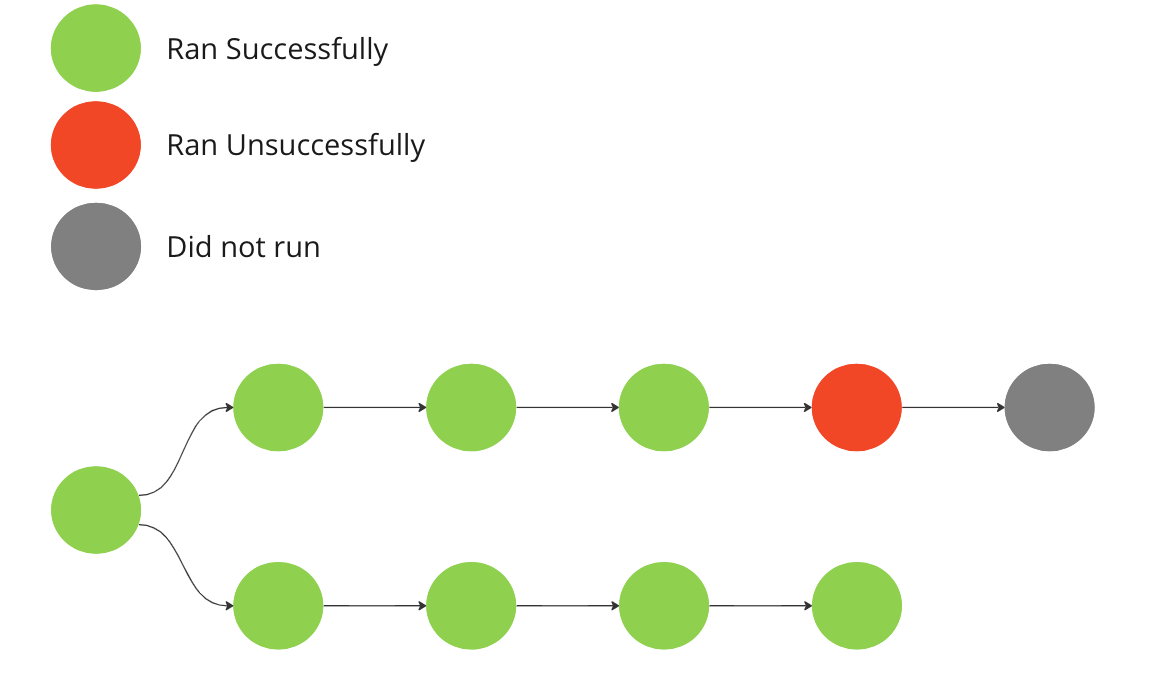
In the diagram, the runner meets a node that cannot run but finds other sections or branches that it can execute.
The client relies on Kedro to execute a substantial pipeline that retrieves data from various sources. Some of the input datasets are manually created, which introduces the possibility of errors if entries are mistyped or omitted. By allowing the pipeline to continue and bypass nodes as they encounter failures, it becomes possible to compile a comprehensive list of data issues during a single run and address them collectively.
In comparison, the default Kedro approach is considerably more time-consuming as it pauses the pipeline upon the failure of a single node, leading to a repetitive cycle of fixing one issue, rerunning the pipeline to encounter the next issue, fixing that, and so on.
Executing all feasible nodes within the pipeline provides an additional advantage. In cases where no data issues arise, completing the pipeline allows the available metrics to be displayed on a BI dashboard, ensuring service continuity. For instance, if only one data source is corrupted, the BI metrics that depend on that specific data need to be withheld, but all others can be showcased. In contrast, the default Kedro behaviour would render all metrics unavailable until the single dataset issue is resolved.
The solution: a customised Kedro runner
As an open-source project, Kedro enables you to define a custom runner for your project. The team took the open-source code for Kedro’s sequential runner and extended it, since the code didn’t need any parallelisation.
The team created a soft-fail runner to transform errors into warnings, allowing the pipeline to continue executing to the best of its ability while providing a report of any nodes that failed, so that data issues can be addressed. At that point, the pipeline run can be finalised by executing only those missing nodes separately, using appropriate Kedro syntax.
The resulting SoftFailRunner is an implementation of AbstractRunner that runs a pipeline sequentially using a topological sort of provided nodes. Unlike the built-in SequentialRunner, this runner does not terminate the pipeline but runs any remaining nodes as long as their dependencies are fulfilled. The SoftFailRunner implementation adds two arguments: --from-nodes and --runner.The essential code for the SoftFailRunner is shown below and the full code can be found on GitHub.
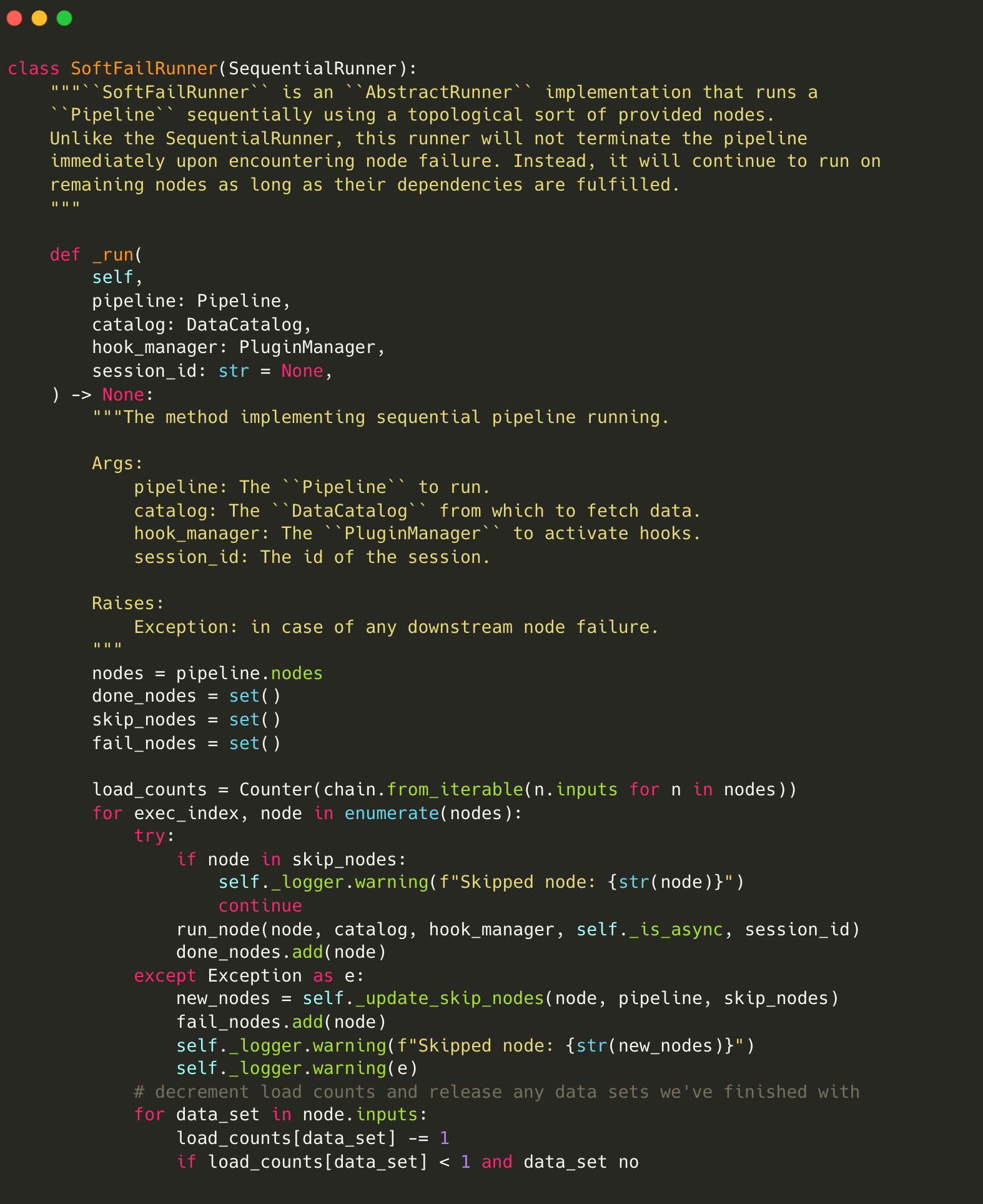
The logic behind the runner is as follows:
Addition of a new
skip_nodesvariable to keep track of which nodes should be skipped.Every time a node is about to run - the
skip_nodeslist is checked.When a node fails, all of its descendants are added into
skip_nodeswith Breadth-first search (BFS).
In summary
The customised Kedro runner was straightforward to create and a satisfactory solution to enable maximum efficiency when handling this particular pipeline and dataset.
“These results could certainly be achieved with an orchestrator, but using an open-source project with customisation is a quick win for delivering business value”.





