
The information an AI agent needs to answer a biomedical question is rarely in one place. In biology, knowledge is scattered across ontologies, databases, drug resources, gene annotations, papers, and custom artifacts produced by individual labs. And each piece of this information has its own identifiers, schemas, and release cycles.
This is a main bottleneck for agents in science. They need to reconstruct what each entity means, trace where they came from, and figure out how conflicting evidence from different sources and time points fits together.
To solve this, agentic data infrastructures are being developed to give agents predictable interfaces so tool calls return consistent outputs. This means that data cannot be treated as a preprocessing step that happens before the agent runs. It has to be designed as a component of the system itself.
OptimusKG was built for this. It is an open biomedical knowledge graph, and the reproducible Kedro-based data infrastructure used to build it, that unifies structured and semi-structured biomedical resources into an ontology-grounded graph. OptimusKG was built for retrieval systems, scientific copilots, and agents that need typed entities, granular properties, and provenance.
Homogenization of structured biomedical knowledge
For scientific knowledge, turning everything into plain text is usually the wrong default. A drug-target interaction, a disease-gene association, and an anatomy-gene expression relation have different evidence, different vocabularies, and carry different provenance. If we flatten them too early, an agent may retrieve something plausible without knowing what kind of fact it is using.
OptimusKG takes the opposite approach. It standardizes the graph enough for agents to traverse it, but not so much that source-specific information disappears.
Every node and edge has an enumerated type. Every entity is grounded in a shared semantic space through ontology alignment. Every node and edge keep granular properties, and provenance is stored next to the facts it supports.
Architecture of the knowledge data layer
The core architectural design choice behind OptimusKG was to build infrastructure that reliably recreates biomedical graphs, rather than producing a single static biomedical graph.
Given the same source versions, configuration, and schema rules, the system should generate the same graph. If an upstream resource changes, we should know what changed. If an edge appears in the final exported graph, we should be able to trace it back to the intermediate tables and source files that produce it. And when a validation rule fails, the pipeline should stop or raise a warning at the point where the error was introduced.
We used Kedro’s data catalog to offer us the primitives necessary to support the architecture of OptimusKG. It functions as the source of truth for every dataset, capturing where it comes from, how it is stored, which schema it follows, and what metadata it carries. This is essential for OptimusKG since it integrates a wide range of biomedical resources, including APIs, FTP downloads, SQL dumps, OWL ontologies, ZIP archives, CSV files, JSON files, and Parquet datasets.
We used Kedro’s dataset abstraction by extending it with custom dataset implementations for formats such as Parquet, JSON, ZIP, SQL dumps, XML, OWL, and CSV. This enabled us to keep source-specific loading logic isolated from the rest of the pipeline, and make downstream transformations operate on a consistent Polars DataFrame interface regardless of whether the original data came from an ontology file, a compressed archive, or a remote service.
For upstream download, OptimusKG declares the origin of each dataset in the catalog and resolves it through provider models using Kedro Hooks. This separation of concerns makes the pipeline easier to maintain, test, and extend. New data sources can be added by implementing the appropriate provider and dataset definitions without changing the transformation logic.
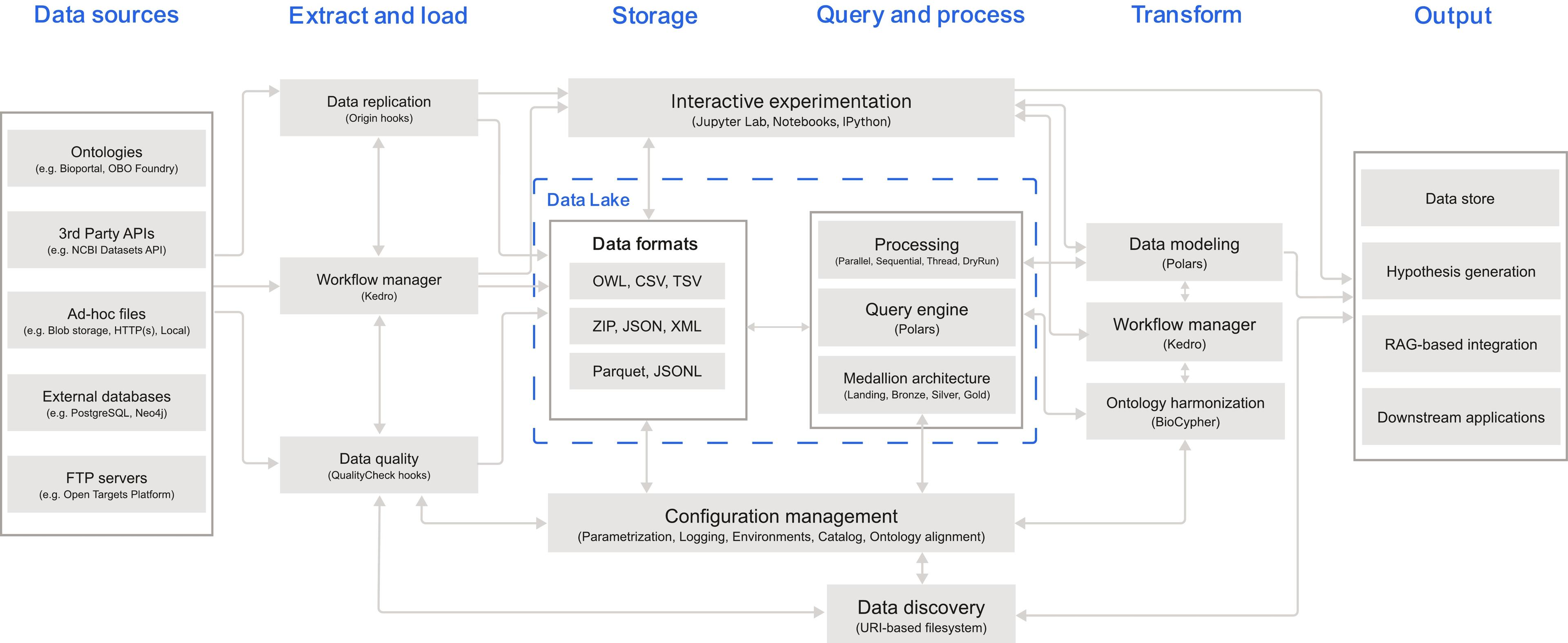
Fig 1. Heterogeneous data sources are ingested in the Landing layer via data replication and Kedro-managed workflows. Configuration management and URI-based data discovery primitives provide governance and traceability. The pipeline uses a medallion architecture to logically organize the data in increasing structure and quality as it flows through each layer (Landing, Bronze, Silver, and Gold). Transformations are done with Polars. The pipeline supports parallel, sequential, and thread execution modes. BioCypher is used to validate that each entity in the graph is ontology-grounded
The data infrastructure follows a medallion architecture. The Landing layer stores replicated raw inputs in the original formats. The Bronze layer converts those raw files into normalized machine-readable representations, mostly columnar tables. The Silver layer performs schema alignment, entity harmonization, and cross-source joins to construct an intermediate graph representation. The Gold layer exports the final graph as Apache Parquet, with separate node and edge tables and typed, nested properties.
This layering makes the pipeline observable. We also relied on Kedro hooks to attach automatic checks to these state transitions. The Origin Hook resolves the declared provider for each Landing dataset and downloads the source if it is missing. For manual or non-public datasets that cannot be downloaded, it creates schema-compliant placeholders, so the public pipeline remains runnable. The Checksum Hook fingerprints datasets and compares them against the expected hashes stored in catalog metadata, making upstream drift visible instead of silent. The Quality Checks Hook runs after transformations, checking naming conventions, rejecting malformed identifiers, and validating relation values against the allowed relation enum.
Configuration and parametrization does the remaining work. Filters, source-specific constants, ontology settings, logging, catalog entries, and environment-specific paths are separated from transformation code; this makes the pipeline portable. The same graph build can run locally, in the cloud, sequentially, or in parallel without writing code.
Final thoughts
OptimusKG was built for agents that want to access biomedical facts. To do that, we created a medallion architecture to build graphs with versioned sources, typed datasets and traceable transformations across the pipeline. We used Kedro since it’s a mature, open-source framework that gave us the right primitives to make this possible.
More about OptimusKG
OptimusKG is developed by the Zitnik Lab as part of a broader effort to build open, reproducible infrastructure for AI. The project is designed to make biomedical knowledge more accessible to researchers and institutions building retrieval systems, scientific copilots, and agentic applications.
If you want to learn more about the project, you can visit the OptimusKG website. Installation guides, tutorials, and technical details are available in the documentation. The research paper describing the methodology and technical evaluation can be found here.
Those interested in the implementation can explore the source code nd contribute through GitHub. Developers who want to work with the graph programmatically can install the Python client from PyPI, and the dataset is also available via Harvard Dataverse.
We welcome feedback, contributions, and collaborations from the community. Building reliable knowledge infrastructure for biology is a collective effort, and we hope OptimusKG can serve as a foundation for the next generation of scientific AI systems.
What is Kedro?
Kedro is an open-source Python framework for structuring and authoring production-ready data and AI pipelines. It brings software engineering best practices—such as modularity, reproducibility, and separation of concerns—to help teams build maintainable, scalable workflows and transition from experimentation to production faster.
Originally developed at QuantumBlack to address the challenges of real-world data science projects, Kedro is now a project of the LF AI & Data Foundation, supported by a growing open-source community.





