
Kedro has a wide range of users, each with different goals and skills. Developing a cohesive tool that caters to all these needs is a challenge, and we’ve previously received feedback about Kedro that it has a steep learning curve and that it’s opinionated or inflexible. In this post we explain how we have made changes to Kedro in the new 0.19 release to tackle one of the most commonly perceived pain points: "There’s a lot of boilerplate!"
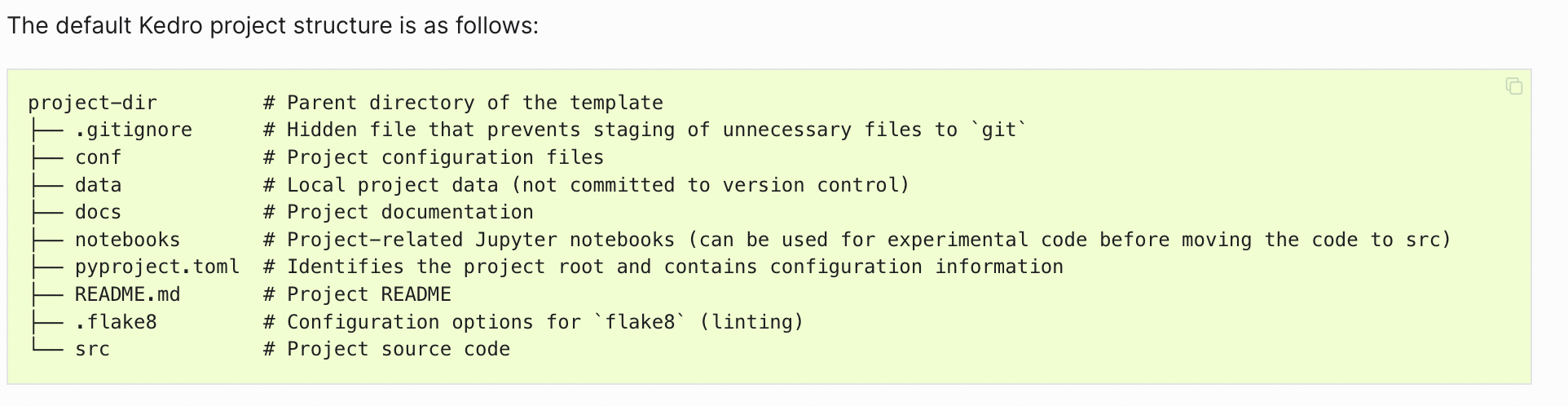
The Kedro project structure
One of the core value propositions of Kedro is its role as a framework for users to adopt software engineering best practices for data science. When you create a new Kedro project, we set it up to follow the template of a typical, well-structured data science codebase, much like Create React App from the front-end world.
Kedro was created with the view that we should include everything in a new data science project that users need for software best practices. Even for users unfamiliar with the reasoning, the philosophy was that it would help to signpost important areas of engineering for study purposes. So a new Kedro project included all the files and directories needed to set up, and extend a project with your own code, run, test, document, visualise and package it.
Hitting the pain point
For inexperienced data scientists, a new project that contains multiple files and folders, configuration and environments, can be confusing and intimidating when you’re unsure what they’re all for. While Kedro’s value is to offer an entrypoint to learning about software engineering best practices, this “everything, everywhere, all at once” approach contributes to a perception of Kedro projects as having a steep learning curve.
Conversely, those experienced with software best practices may also find “all the things” in a new project to be unnecessarily cluttered, particularly if they already have a preferred way of doing things and a preferred standard toolbox for linting, testing or documenting their code. If a team or user has already selected a specific tool for testing, they may prefer not to switch to the one added by Kedro, and so find themselves with redundant code and settings to delete.
Few would argue that Kedro guides users to follow best practice. But for many it is hard to leave behind the notebook environment, even for the longer term prospect of maintainable and productionisable code.
Considering the feedback we’ve received in user research, we decided to offer a simpler project structure to give users a choice as to which elements of the Kedro template they adopt. We recently unveiled this in Kedro 0.19 and the rest of this article explains how to use it.
New in Kedro 0.19: Project customisation
To address the feedback that Kedro was intimidating for new users and too opinionated for advanced users with their own way of doing things, we now enable you to customise what is included in a new project. You can make a basic, empty, project or create a full-featured spaceflights example that includes every tool we recommend. Or you can put something together customised for your particular needs.
We have updated the new project creation flow in Kedro 0.19. The command line interface (CLI) now offers the option to select the tools you’d like to include in the project. The options are as follows, and are described in more detail in the Kedro’s documentation about the new project tools. You can add all tools, none of them or a combination. To list all the tools, type the following:
1kedro new --helpHere’s a summary of what’s available:
Linting: A basic linting setup with Ruff
Testing: A basic testing setup with pytest
Custom Logging: Additional logging options
Documentation: Configuration for basic documentation built with Sphinx
Data Structure: The directory structure for storing data locally
PySpark: Setup and configuration for working with PySpark
Kedro-Viz: Kedro’s native pipeline visualisation tool.
You can also opt to include example pipeline code from the spaceflights starter, based on the combination of tools you included:
The Full Feature Starter (
spaceflights-pyspark-viz) example code is used when you select all available tools, including PySpark and Kedro Viz.The Default Starter (
spaceflights-pandas) code is used when you select any combination of Linting, Testing, Custom Logging, Documentation, and Data Structure, unless you include PySpark or Kedro Viz.The PySpark Starter (
spaceflights-pyspark) is chosen when PySpark is selected with any other tools, unless you select Kedro Viz too, in which case you’ll receive the full-feature starter.The Kedro Viz Starter (
spaceflights-pandas-viz) is included when Kedro Viz is part of your selection, combined with any other tools, unless you select PySpark too, in which case you’ll receive the full-feature starter. .
Each starter example is tailored to demonstrate the capabilities and integrations of the selected tools, offering a practical insight into how they can be utilised in your project.
The following sections explain how to use the new flags to create a new Kedro project.
Create a new Kedro project using a stepwise interactive flow
In the CLI, navigate to the directory in which you would like to create your new Kedro project, and run the following command: kedro new
This will start the new project creation workflow. The first prompt asks you to input a project name.
You are then asked to select which tools to include. Choose from the list using comma separated values (1,2,4), ranges of values (1-3,5-7), a combination of the two (1,3-5,7), or the key words all or none. Skipping the prompt by entering no value will result in the default selection of none. Further information about each of the tools is described in the Kedro documentation that discusses the Kedro tools.
1Project Tools
2=============
3These optional tools can help you apply software engineering best practices.
4To skip this step in future use --tools
5To find out more: <https://docs.kedro.org/en/stable/starters/new_project_tools.html>
6
7Tools
81) Lint: Basic linting with Ruff
92) Test: Basic testing with pytest
103) Log: Additional, environment-specific logging options
114) Docs: A Sphinx documentation setup
125) Data Folder: A folder structure for data management
136) PySpark: Configuration for working with PySpark
147) Kedro-Viz: Kedro's native visualisation tool
15
16Which tools would you like to include in your project? [1-7/1,3/all/none]:
17 [none]:In the final step you are asked whether you want to populate the project with an example spaceflights starters, for which you can answer yes or no. At this point there is a pause while the project is created inside your directory, within a new subdirectory, named according to your choice of project name.
Examples
To create a basic default Kedro project called My-Project with linting and example code:
kedro new ⮐ My-Project ⮐ 1 ⮐ yes ⮐
To create a spaceflights project called spaceflights with all the tools and example code:
kedro new ⮐ spaceflights ⮐ all ⮐ yes ⮐
To create a project, called testproject containing linting, documentation, and PySpark, but no example code:
kedro new ⮐ test project ⮐ 1,4,6 ⮐ no ⮐
The following video illustrates these examples:
Create a new Kedro project from the CLI in one command
You may also specify your project name and tools selection directly from the command line by using flags for --name, --tools and --example. To specify your desired tools you must provide them by name as a comma separated list, choosing none, one or more from the list: lint, test, log, docs, data, pyspark, and viz.
kedro new --name=<project name> --tools=<your tool selection> --example=y or n
Examples
To create a default Kedro project called My-Project with linting and example code:
kedro new --name=My-Project --tools=lint --example=y
To create a spaceflights project called spaceflights with all tools and example code:
kedro new --name=spaceflights --tools=all --example=y
To create a project, called testproject containing linting, documentation, and PySpark, but no example code:
kedro new --name=test project --tools=lint,docs,pyspark --example=n
Create a new Kedro project from a configuration file (advanced)
As an alternative to the interactive project creation workflow, or specifying the flags for your new project you can also supply values to kedro new by providing a YML configuration file to your kedro new command. We won’t discuss this option further here, but you can find out more in the Kedro docs.
Next steps with your new Kedro project
If you found this helpful and now want to start exploring how to use the new project, you can take a look at the documentation. There’s also a full tutorial that explains the spaceflights project in detail, going through the main features of Kedro stepwise. To ask questions, and stay tuned on future releases and updates to Kedro, why not join our Slack community?
Summary
In this article we explained the philosophy behind Kedro and examined how this benefits some users but is potentially seen as a pain point by others. We walked through how a set of changes to Kedro’s new project creation flow, introduced in Kedro 0.19, address the issue of complex starting projects, and illustrate how we are adapting our user experience from feedback.
We have some way to go! We need to help users faced with the new project to understand the value of the structure and how our strong opinions on software best practices can get them code that works in the long term. As part of our drive to get Kedro users up to speed fast, we’ve launched a free video course, which you can find out our YouTube channel.
What's new in Kedro 0.19?
The blog post "Exploring our new release: Kedro 0.19" describes the key enhancements and improvements to Kedro in the recent 0.19 release. In brief, these include:
New project tools to help you create a new Kedro project containing the tools and example code that is customised for your needs.
The build configuration and project metadata are now included in
pyproject.toml.The
kedro-datasetspackage replaceskedro.extras.datasets.Changes to the configuration loader now enable easy access to some of Kedro’s key features from a notebook without needing a full project.
OmegaConfigLoaderis now the only configuration loader in Kedro, and has been extended so you can choose a merge strategy.Enhanced documentation plus a new top-level navigation element to find out more about Kedro-Viz and `kedro-datasets`.





