
Kedro as a Service
Over the years, one of the most requested capabilities from the Kedro community has been the ability to execute pipelines repeatedly inside long-running services and expose them programmatically to external systems.
This capability has become even more important as AI systems for agentic systems.
We’re in the process of developing a Kedro Server API and underlying KedroServiceSession so that structured Kedro pipelines can operate as callable, API-accessible services within larger systems. We’re showing you all what we’ve done so far, and we'll continue to iterate depending on feedback.
The Kedro project was open sourced 7 years ago when execution patterns were primarily designed around batch-oriented workloads, where workflows were triggered independently and execution context was recreated for each run. The model works well for many data processing scenarios, but users have reported that it’s limiting for interactive applications, repeated execution loops, API-driven workflows, dashboards, real-time inference, and particularly for long-running gen AI services. A critical architectural requirement for agentic workflows is an execution framework that is directly callable from external systems.
What we’ve done so far
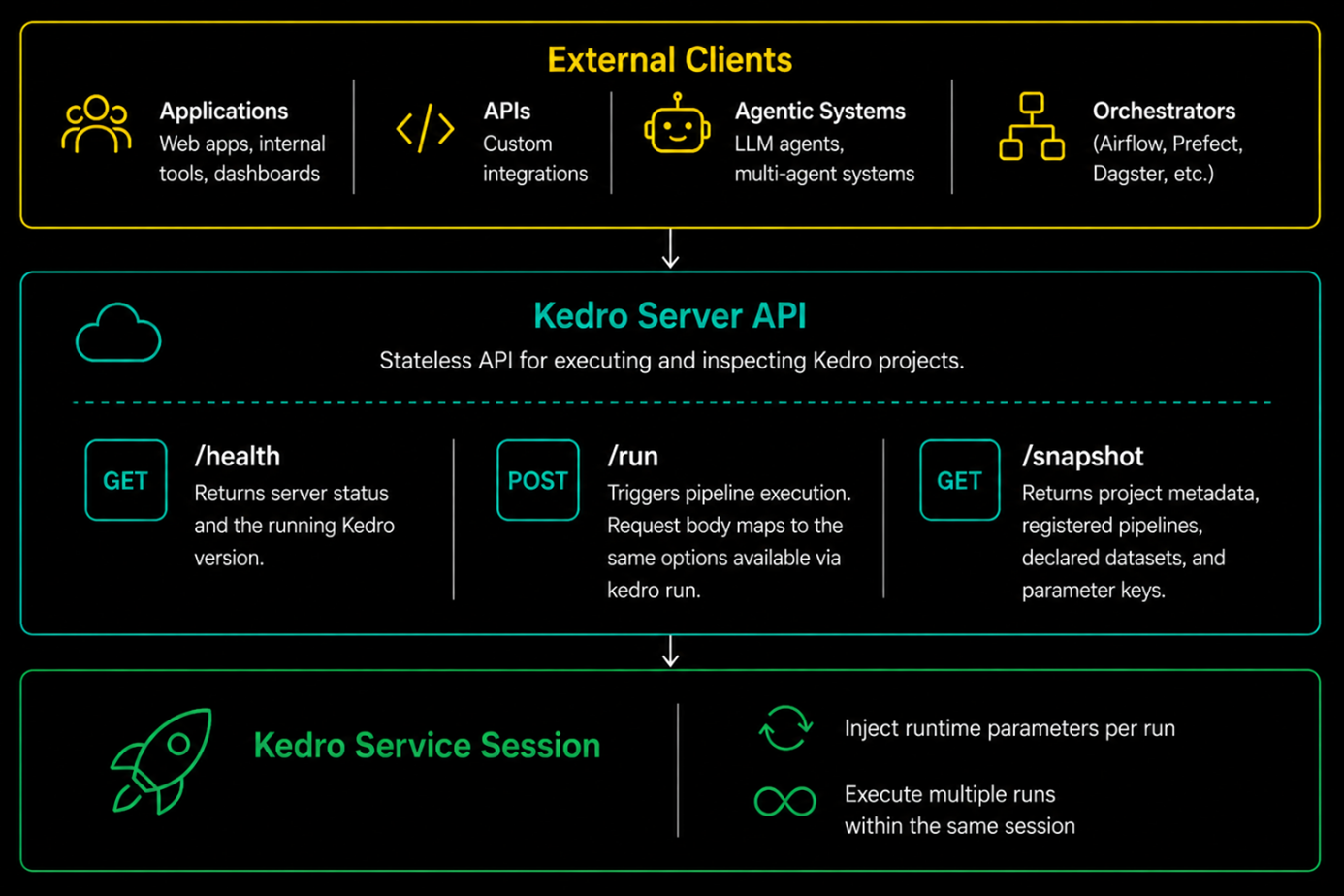
1. Kedro Server API
We’ve recently added a Kedro Server API that offers a way to trigger pipelines by invoking them over HTTP. They can be called programmatically from other applications, and integrated directly into larger systems as callable services. Kedro pipelines are now available as reusable building blocks accessible to any system that can make an HTTP request.
It doesn’t change Kedro's role as a pipeline authoring framework but extends the ways structured Kedro pipelines can participate inside modern AI systems.
The Kedro HTTP Server is a FastAPI-based server that wraps a Kedro project and exposes its pipelines and project metadata as REST endpoints. It can be started with a single CLI command from within a Kedro project: kedro server start
Once running, the server exposes three core endpoints:
GET /health — Returns server status and the running Kedro version. This is the standard liveness check for monitoring and orchestration platforms.
POST /run — Triggers pipeline execution. This is the primary endpoint for service-oriented workflows. The request body maps directly to the same execution parameters available via
kedro run: which pipelines to execute, which nodes to include or exclude, tags, runner type, load versions, and runtime parameters.
For example:
1{
2"pipeline_names": ["scoring"],
3"runtime_params": { "threshold": 0.85 },
4"runner": "SequentialRunner",
5"tags": ["production"]
6}
7GET /snapshot — Returns a read-only inspection snapshot of the Kedro project: project metadata, registered pipelines, declared datasets, and parameter keys. This provides a consistent, queryable view of project structure that can be consumed by external tooling, dashboards, and interfaces such as Kedro-Viz.
2. KedroServiceSession
Traditionally, KedroSession was designed as a short-lived execution context: a pipeline run would create a session, load configuration and catalog objects, execute the workflow, and then terminate.
KedroServiceSession extends this model by enabling persistent, repeatable execution within the same running process. Unlike the standard KedroSession, which is designed for a single run, KedroServiceSession can accept multiple run() calls on the same session instance. Project-level state such as the hook manager is initialized once and carried across runs, while each individual execution still loads its own configuration and data catalog so that runs can be kept isolated and reproducible.
Each run can also receive its own runtime parameters, enabling callers to inject dynamic inputs, such as model thresholds, or request-specific values, without changing pipeline code or project configuration.
It means the execution model for Kedro pipelines is more service-oriented, as it supports patterns such as model serving APIs, interactive applications, agentic workflows, and other systems that need repeated execution with dynamic inputs.
KedroServiceSession is currently under active development, and future iterations are exploring pre-loading of execution resources such as the catalog and configuration to further reduce per-run overhead to make it better suited to latency-sensitive workloads as the feature matures.
Example Use Cases
The following examples represent a subset of the types of workflows enabled by the KedroServiceSession and Server API, intended to give users a few concrete examples of how these capabilities could be applied in practice.
Use Case 1: Model Inference API
If you have a Kedro pipeline that loads a trained model, runs feature engineering, and produces predictions, you no longer need to trigger it exclusively as a scheduled batch job. With the HTTP server, you can wrap that same pipeline as a callable scoring service. Any upstream application, for example, a web app, a data platform, or another service can send a run request with runtime parameters identifying the input data, receive a run ID and status in response, and read results from the output dataset. You do not need to change any pipeline code or project structure to make this work
Use Case 2: LLM Agent Tool Integration
If you are building an agentic LLM system using frameworks such as LangChain, you can expose a Kedro pipeline as one of the tools your agent calls. Each iteration of the agent can pass its dynamic inputs as runtime parameters in the request, and read structured results back. This gives your agent-driven workflow access to the full observability, configuration management, and reproducibility guarantees of the Kedro framework, without requiring the agent to manage execution context directly. You can use this pattern for retrieval pipelines, evaluation steps, scoring workflows, or any structured processing step that benefits from being versioned and auditable.
What's Next?
The new Service Session capabilities are about an evolution toward more interactive and service-oriented execution models inside Kedro. We value each and every comment on what we’ve done so far.
Future iterations will explore pre-loading of execution resources such as the catalog and configuration to further reduce per-run overhead, for latency-sensitive workloads.
The goal is not to move Kedro away from its core identity as a pipeline authoring framework, but to extend how structured Kedro pipelines can operate inside interactive AI systems.
As we discussed in our recent article on engineering discipline for gen AI systems, the challenge is often not model quality, but system architecture. As AI workflows evolve, they require stronger foundations around execution, reproducibility, observability, and maintainability. Kedro’s goal is to provide that stable foundation so even as execution models evolve, workflows remain modular, traceable, and production-ready.
For more information, check out our GitHub repo and docs. Join our Slack workspace!
Acknowledgements: Special thanks to Ankita Katiyar who led the development of the features discussed in this blog post!





