
This article describes the modern data and ML tooling landscape. We explain the key categories of tools, in terms of what they are best suited for and how they complement one another. Most importantly, we describe where Kedro fits within this ecosystem.
Why structure matters
Suppose you are a data scientist, or an AI/ML or data engineer, starting work on a new data experiment. At first, the task feels manageable. You build a few steps, perhaps in a notebook or a simple Python script, and the experiment works well.
As you iterate, however, the scope expands. New data sources are introduced. Transformations grow more complex. Maybe one or more agents need to be integrated into the pipeline. What started as a small experiment gradually evolves into something much larger. After many hours of work, you are confident that the code performs well. And then a request arrives: “Can we move this into production?”
The realization dawns. What worked well for exploration is not ready for deployment. Parts of the code need to be rewritten. Dependencies are implicit. Configuration is scattered. The structure no longer feels sustainable. At this point, important questions start running through your mind:
How do I structure the code to avoid a tangle of implicit dependencies?
How do I keep configuration (paths, parameters, environments) out of the core logic?
How do I make sure others can understand, extend, and reuse what I am building?
You begin to feel the need for clearer guidelines so that you can write code that is production-ready, well-organized, and built to evolve.
Now scale this scenario further. Imagine the project is not only in production, but it needs to be adopted across your organization. Multiple teams are now working on it, each adapting parts of it to their own specific needs. For these teams to collaborate effectively, they need access to the same codebase, to share a common language, and agree on how to structure projects, define components, and create pipelines.
Without a common foundation, scaling becomes incredibly complex. And as projects grow, so does the need for observability: teams must be able to understand how components interact, trace data and execution flows, and quickly identify bottlenecks or failures. Over time, experimental shortcuts turn into structural debt that requires frequent rewrites. This leads to increased operational overhead and risk. What once worked for a single team becomes costly and fragile at scale.
Collaboration thrives when teams share best practices and consistent conventions.
A crowded ecosystem
You begin exploring how other companies tackle this challenge and the tools they rely upon. Research reveals a crowded ecosystem: Python frameworks that help you set up project structure and develop pipelines efficiently; orchestration platforms that schedule and monitor workflows; tools that blur the line between pipeline definition and orchestration; notebook-based environments for experimentation; and a growing set of generative AI (gen AI) frameworks focused on agentic behavior and reasoning.
These tools are often discussed together, but they operate at different layers of the stack. In practice, real-world systems typically combine several tools rather than rely on any single solution.
The real challenge in modern data and machine learning work is knowing when exploratory work is heading for production, and what kind of structure that requires. This challenge has become even more pronounced with the rise of gen AI systems because these are often deployed into production environments at an early stage, sometimes before teams have had time to establish robust structure, clear modularization, and maintainable project conventions.
The aim of this article is not to present Kedro as a one-size-fits-all solution, but to clarify where it fits in the ecosystem.
Kedro as a foundation for scalable pipelines
As we’ve described, a common scenario is a project that starts as proof of concept but rapidly grows: more datasets, more transformations, and eventually more contributors. Even if the work is still exploratory and not yet running in a production environment, its trajectory is clear.
At this stage, the first challenge is to structure the code so that it follows clear conventions and sound engineering practices as it evolves. This is less about orchestration or deployment, and more about establishing a maintainable foundation early on, so the work does not need to be rewritten when it later becomes production-critical.
Frameworks such as Kedro are designed specifically for this purpose. They focus on how pipeline logic is expressed and organized, helping teams build data workflows that are easier to reason about, test, and extend as complexity increases.
Kedro is well suited to this stage because it provides an opinionated but flexible structure from the outset:
A pipeline is defined as a directed acyclic graph (DAG) of pure Python functions. This makes dependencies explicit and keeps business logic modular and testable. Because nodes are just functions, they are easy to unit test, reuse, and reason about. The DAG structure also makes execution order transparent, reducing hidden dependencies and improving maintainability as pipelines grow.

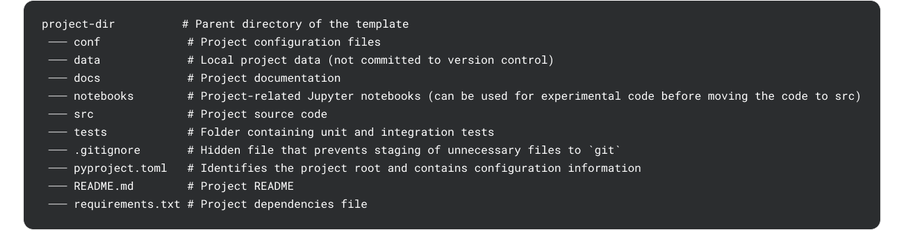
The default project template provides a rich, comprehensive structure. The standardized layout helps teams quickly understand how a project is organized, making onboarding faster and cross-team collaboration smoother.
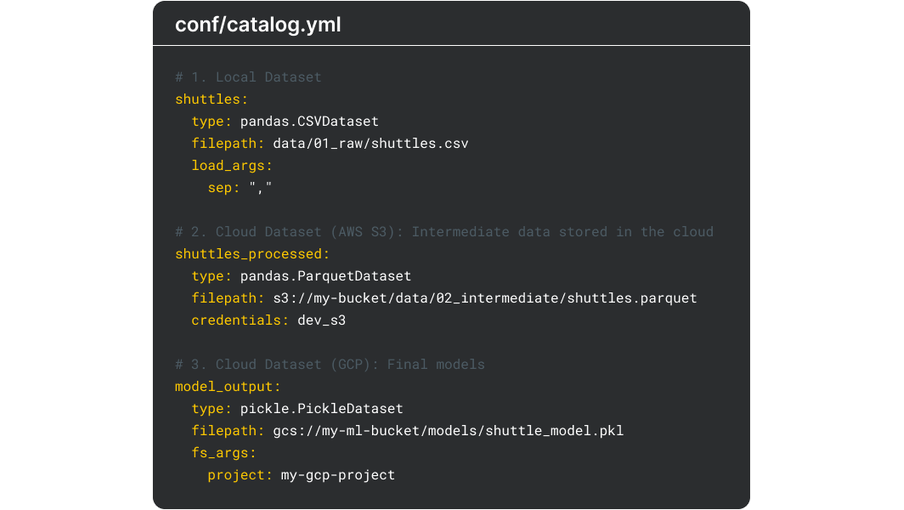
Data access is abstracted through a data catalog. It formalizes how data is accessed, versioned, and managed across a project, preventing file paths and storage logic from being scattered throughout the codebase. This separation of concerns simplifies environment changes, for example, local to cloud, improves reproducibility, and creates a consistent contract between data and logic.
Configuration and parameters are externalized rather than embedded in code. By separating configuration from business logic, projects become more flexible and easier to adapt across environments. Parameters can be adjusted without modifying code, which reduces the risk of errors and simplifies experimentation, deployment, and collaboration across teams.

The result is a codebase that is easier to maintain and easier to evolve. Pipeline logic is separated from how and where it runs. The same code can be executed locally, scheduled by an orchestrator, or deployed in different environments without changing the core implementation, which makes testing and reuse straightforward. Teams can collaborate without having to constantly rediscover conventions or reverse-engineering intent.
Kedro-Viz complements these design principles by providing an interactive way to explore pipelines, nodes, and datasets, adding a layer of observability to the development experience. Instead of gathering information about workflows purely through code, users can visually inspect how data moves through the system, which improves comprehension and communication—especially as pipelines become more complex. Beyond static visualization, Kedro-Viz also surfaces run status information, showing whether individual nodes or pipelines have succeeded, failed, or been skipped. This execution-level feedback makes it easier to debug issues, trace failures, and understand pipeline behavior during and after runs.

In short, Kedro aims to provide a solid foundation for any data engineering and data science project.
When orchestration enters the picture
As pipelines mature, new requirements typically emerge: reliable scheduling, cross-workflow dependency management, retries on failure, logging, alerting, access control, and operational visibility. This is the domain of orchestration tools, which are responsible for when, where, and under what conditions pipelines execute.
There are different orchestration solutions available in the ecosystem. For example:
Apache Airflow is a widely adopted, battle-tested orchestrator known for its operational maturity and rich ecosystem
Dagster offers a modern developer experience with strong observability and an asset-oriented approach to pipeline modeling
Prefect focuses on flexible, Python-native workflow orchestration with an emphasis on ease of use and dynamic execution
Kedro integrates with these and other leading orchestrators, enabling teams to combine software engineering best practices with production-grade scheduling, monitoring, and scalability to gain the best of both worlds.
Some orchestration tools enable teams to define pipelines directly within the orchestrator itself. For instance, with Dagster, you can define assets and jobs using its own decorators and framework conventions, while Prefect uses Python-native @flow and @task decorators to define pipeline structure and logic directly within its runtime. For certain use cases, particularly early-stage projects or straightforward workflows, this can accelerate initial deployment and reduce setup overhead by keeping everything in one place. However, defining pipelines inside an orchestrator can also tightly couple business logic to operational concerns. As a result, pipeline structure, execution semantics, and deployment environments may become closely bound to a single platform.
Kedro takes a different approach and separates the pipeline definitions from orchestration. While this separation introduces deliberate structure upfront, it delivers long-term advantages and enables faster iteration and more sustainable development as projects grow in scope and complexity.
Kedro remains agnostic about how and where pipelines are run. Kedro pipelines can be executed locally, scheduled via Airflow, Dagster or Prefect, or integrated into custom platforms and any major Cloud providers.
By separating pipeline definition from orchestration and deployment, Kedro remains platform-agnostic, enabling teams to adopt or change orchestration layers and cloud providers without reshaping their core business logic. In return, they gain portability and a framework-level standard that travels with their code.
Kedro does not replace orchestration tools. Instead, it complements them by ensuring that the pipelines they execute are well-structured, modular, maintainable, and reproducible.
Agentic workflows and gen AI pipelines
The rise of gen AI has added another layer to the ecosystem. Frameworks such as LangGraph and AutoGen enable agentic workflows, in which components reason, interact with tools, and make decisions autonomously.
Agent frameworks are powerful, but they typically address a specific slice of a broader system. An agent may handle enrichment, classification, or decision-making, while upstream components ingest data, and downstream components persist results, evaluate performance, or trigger actions.
Kedro fits naturally around these workflows. Agentic logic can live inside individual nodes, while Kedro provides structure for the end-to-end pipeline, enabling a combination of traditional data processing, machine learning, and gen AI components.
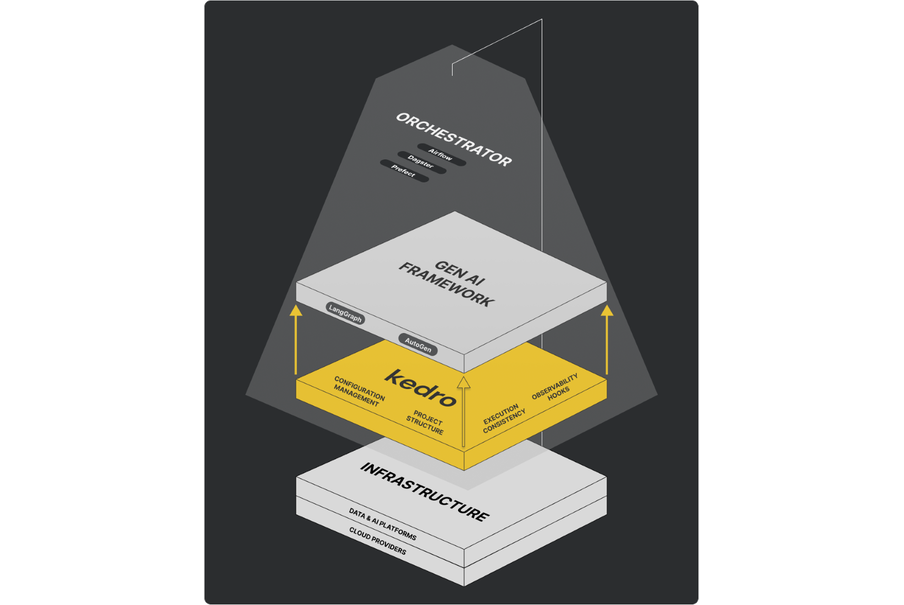
It is important to be clear about boundaries. Kedro is not an agent framework. It does not define how agents reason, which language models to use, or how tools should behave. Instead, it provides the production backbone around gen AI workflows: project structure, configuration management, execution consistency, and observability hooks.
Making sense of the ecosystem
At this point, the broader structure of the ecosystem should be clearer:
Frameworks such as Kedro focus on structure and efficient pipeline development.
Orchestrators like Airflow, Dagster, and Prefect manage scheduling, execution, retries, and monitoring.
Gen AI frameworks such as LangChain and AutoGen enable LLM interaction and agentic workflows, offering model-agnostic integration alongside structured multi-agent orchestration and tool use.
Most of these tools are complementary rather than competitive, and where there is overlap in functionality, each has a distinct value proposition. Teams must decide which trade-offs they are willing to make, particularly between structure, flexibility, and speed. The real challenge lies in understanding where each tool belongs and how they fit together.
Kedro’s role in this ecosystem is to act as the structural backbone; it is the part of the system that remains stable even as execution platforms, models, or orchestration technologies evolve.
When you should (and should not) use Kedro
To recap, Kedro delivers the most value once work moves beyond isolated experiments and teams begin to prioritize modularity, reproducibility, and long-term maintainability. For teams that value flexibility and a platform-agnostic approach, Kedro provides a strong foundation: it offers clear structure without locking you into a specific orchestrator, execution engine, or cloud provider, and can adapt as your technology stack evolves.
Kedro is intentionally not a pure orchestrator. Instead, it focuses on how pipeline logic is structured and expressed, while remaining compatible with a wide range of execution and orchestration environments. Likewise, it is not designed to replace gen AI or modeling frameworks, but to integrate with them as part of a broader ecosystem.
Kedro is a strong fit when a project grows beyond a single notebook or script and involves multiple contributors, requires reusable logic across teams, or demands reproducibility over time. It is designed for pipelines that are expected to evolve and persist over months or years, rather than days. To help teams make a transition to use Kedro, the Kedro MCP server can assist in automatically turning experimental notebooks into production-ready Kedro projects, lowering the barrier from exploration to scalable, maintainable pipelines.
When teams are vibe coding with LLMs, the code generated is often unstructured and difficult to maintain. Kedro's opinionated project layout gives that AI-generated code a home, making it easier for humans to review, extend, and hand off. This reduces the risk of quick experiments hardening into fragile legacy code.
Structure begins to pay off when complexity and collaboration reach a point where informal patterns no longer scale.
More about Kedro
Kedro is an open-source project with broad industry adoption. It records over seven million downloads annually and more than ten thousand GitHub stars, and is used by teams across sectors to build production-grade data and machine learning systems.
Kedro is supported by a full-time development team and is part of the LF AI & Data Foundation, providing a neutral, vendor-independent governance model that supports long-term sustainability and community-driven development. Beyond the core framework, Kedro is supported by an active and growing open-source community. Contributors and users share patterns, extensions, and real-world experience, helping the project evolve in response to practical needs. A growing list of blog posts, videos and projects that use Kedro can be found in the awesome-kedro GitHub repository.
Kedro is also backed by extensive documentation. This includes tutorials, example projects, coffee chats, and dedicated sections for each part of the tool, with code snippets ranging from introductory features to more advanced use cases. Teams can get started quickly using a ready-to-use project template, which includes sample datasets and enables users to train their first model with just a few commands from the terminal.
In a landscape defined by rapid change—new models, new platforms, and new orchestration tools—structure is one of the few investments that consistently compounds over time.
Kedro’s value lies not in replacing other tools, but in providing a stable foundation as everything else evolves. To find out more about Kedro, reach out to us on Slack.





