
This article guides data practitioners on how to set up a Kedro project to use the new SparkStreaming Kedro dataset, with example use cases, and a deep-dive on some design considerations. It's meant for data practitioners familiar with Kedro so we'll not be covering the basics of a project, but you can familiarise yourself with them in the Kedro documentation.
What is Kedro?
Kedro is an open-source Python framework for structuring and authoring production-ready data and AI pipelines. It brings software engineering best practices—such as modularity, reproducibility, and separation of concerns—to help teams build maintainable, scalable workflows and transition from experimentation to production faster.
Originally developed at QuantumBlack to address the challenges of real-world data science projects, Kedro is now a project of the LF AI & Data Foundation, supported by a growing open-source community.
What are Kedro datasets?
Kedro datasets are abstractions for reading and loading data, designed to decouple these operations from your business logic. These datasets manage reading and writing data from a variety of sources, while also ensuring consistency, tracking, and versioning. They allow users to maintain focus on core data processing, leaving data I/O tasks to Kedro.
What is Spark Structured Streaming?
Spark Structured Streaming is built on the Spark SQL engine. You can express your streaming computation the same way you would express a batch computation on static data, and the Spark SQL engine will run it incrementally and continuously and update the final result as streaming data continues to arrive.
Integrating Kedro and Spark Structured Streaming
Kedro is easily extensible for your own workflows and this article explains one of the ways to add new functionality. To enable Kedro to work with Spark Structured Streaming, a team inside QuantumBlack Labs developed a new Spark Streaming Dataset, as the existing Kedro Spark dataset was not compatible with Spark Streaming use cases. To ensure seamless streaming, the new dataset has a checkpoint location specification to avoid data duplication in streaming use cases and it uses .start() at the end of the _save method to initiate the stream.
Set up a project to integrate Kedro with Spark Structured streaming
The project uses a Kedro dataset to build a structured data pipeline that can read and write data streams with Spark Structured Streaming and process data streams in realtime. You need to add two separate Hooks to the Kedro project to enable it to function as a streaming application.
Integration involves the following steps:
Create a Kedro project.
Register the necessary PySpark and streaming related Hooks.
Configure the custom dataset in the
catalog.ymlfile, defining the streaming sources and sinks.Use Kedro’s new dataset for Spark Structured Streaming to store intermediate dataframes generated during the Spark streaming process.
Create a Kedro project
Ensure you have installed a version of Kedro greater than version 0.18.9 and kedro-datasets greater than version 1.4.0.
1pip install kedro==0.18 kedro-datasets~=1.4.0Create a new Kedro project using the Kedro pyspark starter:
1kedro new --starter=pysparkRegister the necessary PySpark and streaming related Hooks
To work with multiple streaming nodes, two hooks are required. The first is for integrating Pyspark: see Build a Kedro pipeline with PySpark for details. You will also need a Hook for running a streaming query without termination unless an exception occurs.
Add the following code to src/$your_kedro_project_name/hooks.py:
1 from kedro.framework.hooks import hook_impl
2 from pyspark import SparkConf
3 from pyspark.sql import SparkSession
4
5 class SparkHooks:
6 @hook_impl
7 def after_context_created(self, context) -> None:
8 """Initialises a SparkSession using the config
9 defined in project's conf folder.
10 """
11
12 # Load the spark configuration in spark.yaml using the config loader
13 parameters = context.config_loader.get("spark*", "spark*/**")
14 spark_conf = SparkConf().setAll(parameters.items())
15
16 # Initialise the spark session
17 spark_session_conf = (
18 SparkSession.builder.appName(context._package_name)
19 .enableHiveSupport()
20 .config(conf=spark_conf)
21 )
22 _spark_session = spark_session_conf.getOrCreate()
23 _spark_session.sparkContext.setLogLevel("WARN")
24
25 class SparkStreamsHook:
26 @hook_impl
27 def after_pipeline_run(self) -> None:
28 """Starts a spark streaming await session
29 once the pipeline reaches the last node
30 """
31
32 spark = SparkSession.builder.getOrCreate()
33 spark.streams.awaitAnyTermination()Register the Hooks in src/$your_kedro_project_name/settings.py:
1"""Project settings. There is no need to edit this file unless you want to change values
2 from the Kedro defaults. For further information, including these default values, see
3 https://kedro.readthedocs.io/en/stable/kedro_project_setup/settings.html."""
4
5 from streaming.hooks import SparkHooks, SparkStreamsHook
6
7 HOOKS = (SparkHooks(), SparkStreamsHook())
8
9 # Instantiated project hooks.
10 # from streaming.hooks import ProjectHooks
11 # HOOKS = (ProjectHooks(),)
12
13 # Installed plugins for which to disable hook auto-registration.
14 # DISABLE_HOOKS_FOR_PLUGINS = ("kedro-viz",)
15
16 # Class that manages storing KedroSession data.
17 # from kedro.framework.session.shelvestore import ShelveStore
18 # SESSION_STORE_CLASS = ShelveStore
19 # Keyword arguments to pass to the `SESSION_STORE_CLASS` constructor.
20 # SESSION_STORE_ARGS = {
21 # "path": "./sessions"
22 # }
23
24 # Class that manages Kedro's library components.
25 # from kedro.framework.context import KedroContext
26 # CONTEXT_CLASS = KedroContext
27
28 # Directory that holds configuration.
29 # CONF_SOURCE = "conf"
30
31 # Class that manages how configuration is loaded.
32 # CONFIG_LOADER_CLASS = ConfigLoader
33 # Keyword arguments to pass to the `CONFIG_LOADER_CLASS` constructor.
34 # CONFIG_LOADER_ARGS = {
35 # "config_patterns": {
36 # "spark" : ["spark*/"],
37 # "parameters": ["parameters*", "parameters*/**", "**/parameters*"],
38 # }
39 # }
40
41 # Class that manages the Data Catalog.
42 # from kedro.io import DataCatalog
43 # DATA_CATALOG_CLASS = DataCatalogHow to set up your Kedro project to read data from streaming sources
Once you have set up your project, you can use the new Kedro Spark streaming dataset. You need to configure the data catalog, in conf/base/catalog.yml as follows to read from a streaming JSON file:
1raw_json:
2 type: spark.SparkStreamingDataSet
3 filepath: data/01_raw/stream/inventory/
4 file_format: jsonAdditional options can be configured via the load_args key.
1int.new_inventory:
2 type: spark.SparkStreamingDataSet
3 filepath: data/02_intermediate/inventory/
4 file_format: csv
5 load_args:
6 header: TrueHow to set up your Kedro project to write data to streaming sinks
All the additional arguments can be kept under the save_args key:
1processed.sensor:
2 type: spark.SparkStreamingDataSet
3 file_format: csv
4 filepath: data/03_primary/processed_sensor/
5 save_args:
6 output_mode: append
7 checkpoint: data/04_checkpoint/processed_sensor
8 header: TrueNote that when you use the Kafka format, the respective packages should be added to the spark.ymlconfiguration as follows:
1spark.jars.packages: org.apache.spark:spark-sql-kafka-0-10_2.12:3.3.1 Design considerations
Pipeline design
In order to benefit from Spark's internal query optimisation, we recommend that any interim datasets are stored as memory datasets.
All streams start at the same time, so any nodes that have a dependency on another node that writes to a file sink (i.e. the input to that node is the output of another node) will fail on the first run. This is because there are no files in the file sink for the stream to process when it starts.
We recommended that you either keep intermediate datasets in memory or split out the processing into two pipelines and start by triggering the first pipeline to build up some initial history.
Feature creation
Be aware that windowing operations only allow windowing on time columns.
Watermarks must be defined for joins. Only certain types of joins are allowed, and these depend on the file types (stream-stream, stream-static) which makes joining of multiple tables a little complex at times. For further information or advice about join types and watermarking, take a look at the PySpark documentation or reach out on the Kedro Slack workspace.
Logging
When initiated, the Kedro pipeline will download the JAR required for the Spark Kafka. After the first run, it won't download the file again but simply retrieve it from where the previously downloaded file was stored.
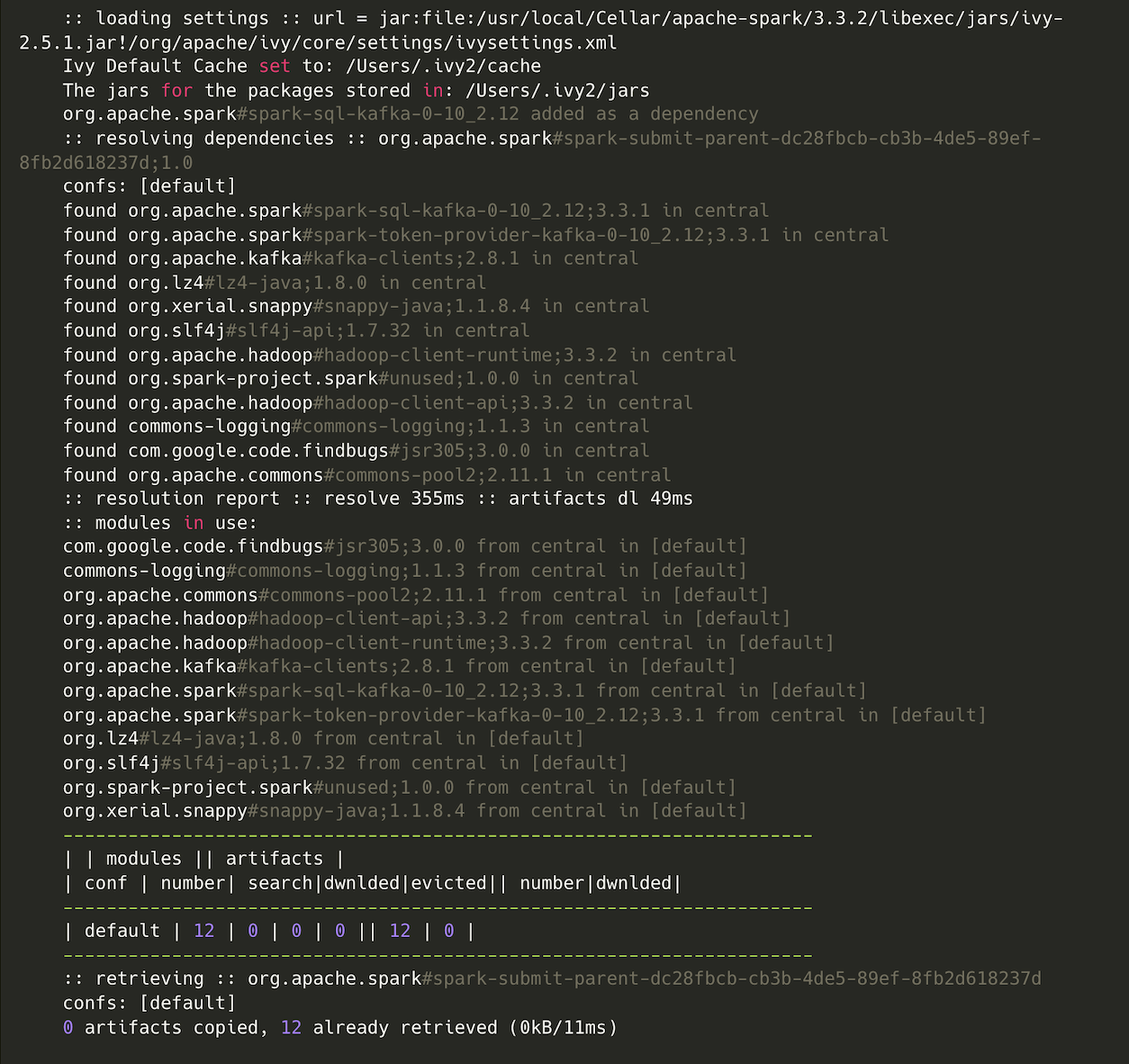
For each node, the logs for the following will be shown: Loading data, Running nodes, Saving data, Completed x out of y tasks.
The completed log doesn't mean that the stream processing in that node has stopped. It means that the Spark plan has been created, and if the output dataset is being saved to a sink, the stream has started.
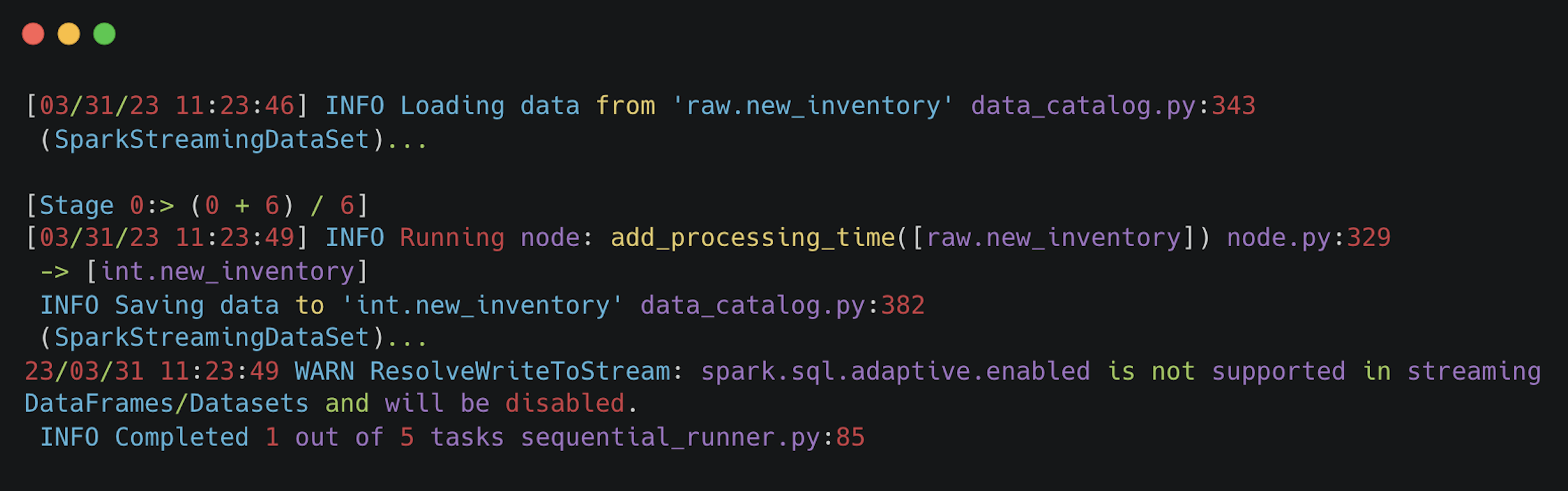
Once Kedro has run through all the nodes and the full Spark execution plan has been created, you'll see INFO Pipeline execution completed successfully.
This doesn't mean the stream processing has stopped as the post run hook keeps the Spark Session alive. As new data comes in, new Spark logs will be shown, even after the "Pipeline execution completed" log.
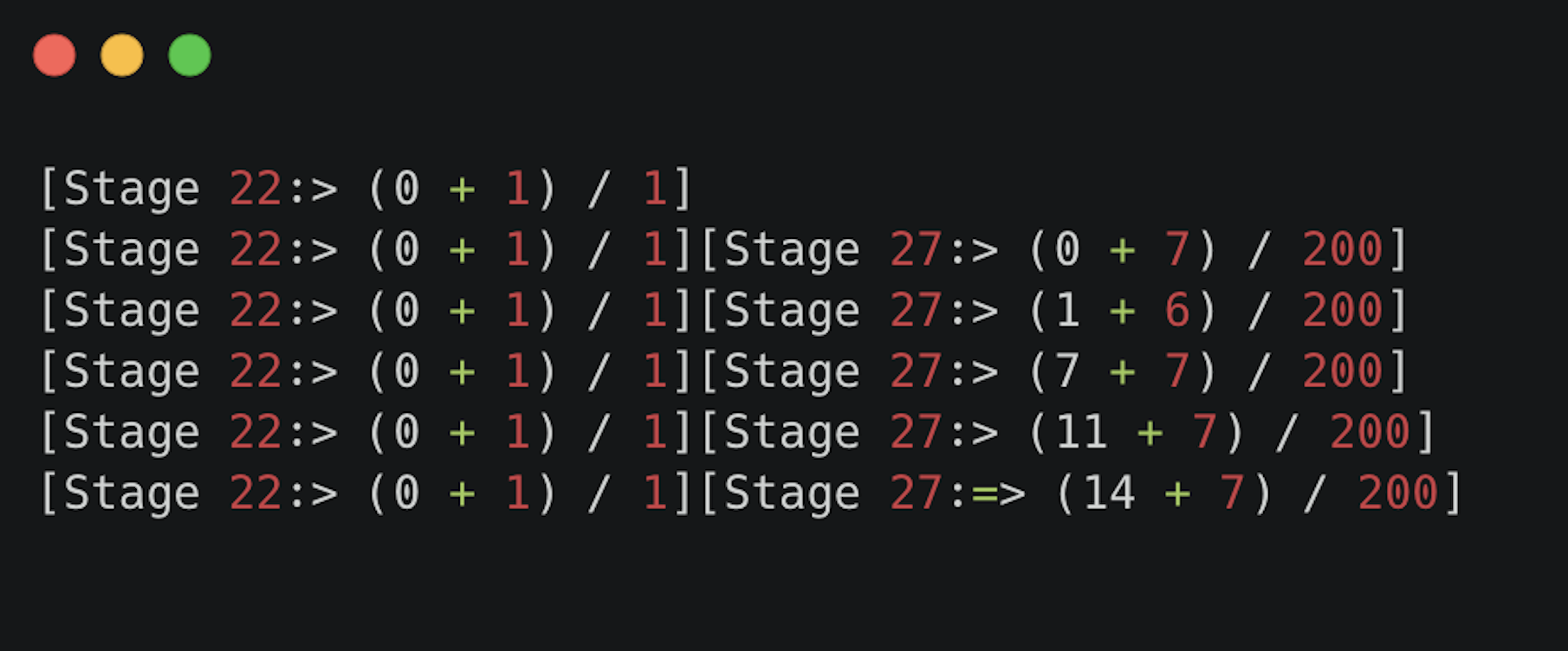
If there is an error in the input data, the Spark error logs will come through and Kedro will shut down the SparkContext and all the streams within it.
In summary
In this article, we explained how to take advantage of one of the ways to extend Kedro by building a new dataset to create streaming pipelines. We created a new Kedro project using the Kedro pysparkstarter and illustrated how to work with Hooks, adding them to the Kedro project to enable it to function as a streaming application. The dataset was then easy to configure through the Kedro data catalog, making it possible to use the new dataset, defining the streaming sources and sinks.
There are currently some limitations because it is not yet ready for use with a service broker, e.g. Kafka, as an additional JAR package is required.
If you want to find out more about the ways to extend Kedro, take a look at the advanced Kedro documentation for more about Kedro plugins, datasets, and Hooks.
Contributors
This post was created by Tingting Wan, Tom Kurian, and Haris Michailidis, who are all Data Engineers in the London office of QuantumBlack, AI by McKinsey.
Recently on the Kedro blog
Recently published on the Kedro blog:
We’re always looking for collaborators to write about their experiences using Kedro. Get in touch with us on our Slack workspace to tell us your story!





