
In your Kedro journey, have you ever...
...slurped up large amounts of data into memory, instead of pushing execution down to the source database/engine?
...prototyped a node in pandas, and then rewritten it in PySpark/Snowpark/some other native dataframe API?
...implemented a proof-of-concept solution in 3-4 months on data extracts, and then struggled massively when you needed to move to running against the production databases and scale out?
...insisted on using Kedro across the full data engineering/data science workflow for consistency (fair enough), although dbt would have been the much better fit for non-ML pipelines, because you essentially needed a SQL workflow?
If so, read on!
The dev-prod dilemma
I began using Kedro over five years ago, for everything from personal projects to large client engagements. Most Kedro users would agree with my experience—Kedro excels in the proof-of-concept/development phase. In fact, Kedro originates from QuantumBlack, AI by McKinsey, and it's no surprise that many other data consultancies and data science teams adopt Kedro to deliver quality code from the ground up. It helps data engineers, data scientists and machine learning engineers collaboratively build end-to-end data pipelines without throwing basic software engineering principles out the window.
In the development phase, teams often work off of data extracts—CSVs, dev databases and, everyone's favorite, Excel files. Kedro's connector ecosystem, Kedro-Datasets, makes it easy. Datasets expose a unified interface to read data from and write data to a plethora of sources. For most datasets, this involves loading the requested data into memory, processing it in a node (e.g. using pandas), and saving it back to some—often the same—place.
Unfortunately, deploying the same data pipelines in production often doesn't work as well as one would hope. When teams swap out data extracts for production databases, and data volumes multiply, the solution doesn't scale. A lot of teams preemptively use (Py)Spark for their data engineering workloads; Kedro has offered first-class support for PySpark since its earliest days for exactly this reason. However, Spark code still frequently underperforms code executed directly on the backend engine (e.g. BigQuery), even if you take advantage of predicate pushdown in Spark.
In practice, a machine learning (software) engineer often ends up rewriting proof-of-concept code to be more performant and scalable, but this presents new challenges. First, it takes time to reimplement everything properly in another technology, and developers frequently underestimate the effort required. Also, rewritten logic, intentionally or not, doesn't always correspond 1:1 to the original, leading to unexpected results (read: bugs). Proper testing during development can mitigate, but not eliminate, correctness issues, but expecting all data science code to be unit tested is wishful thinking. Last but not least, business stakeholders don't always understand why productionising code takes so much time and resources—after all, it worked before! Who knows? Maybe scaling data engineering code shouldn't be so hard...
Given the ubiquity of pandas during the development phase, some execution engines started supporting pandas-compatible or similar Python dataframe APIs, such as the pandas API on Spark and BigQuery DataFrames. Case studies, like this one from Virgin Hyperloop One, demonstrate how these solutions can accelerate the scaling process for data-intensive code. That said, building and maintaining a pandas-compatible API requires significant commitment from the engine developer, so no panacea exists.
The SQL solution
Thankfully, there exists a standardised programming language that every database, and more-or-less every major computation framework, supports: SQL! (Although that begs the question of how standardised is the SQL standard? Gil Forsyth's PyData NYC 2022 talk demonstrates challenges arising from differences between SQL dialects. Even the dbt-labs/jaffle_shop GitHub repository README disclaims, "If this steps fails, it might mean that you need to make small changes to the SQL in the models folder to adjust for the flavor of SQL of your target database").
If you like SQL, dbt provides a battle-tested framework for defining and deploying data transformation workflows. As of February 2022, over 9,000 companies were using dbt in production. The Kedro team frequently recommends it for the T in ELT (Extract, Load, Transform) workflows. Kedro and dbt share similar self-stated goals: Kedro empowers data teams to write reproducible, maintainable, and modular Python code, and "dbt is a SQL-first transformation workflow that lets teams quickly and collaboratively deploy analytics code following software engineering best practices."
"When I learned about Kedro (while at dbt Labs), I commented that it was like dbt if it were created by Python data scientists instead of SQL data analysts (including both being created out of consulting companies)."
—Cody Peterson, Technical Product Manager @ Voltron Data
"What if I don't want to use SQL?"
This post isn't going to enter the SQL vs. Python debate. Nevertheless, many teams and data scientists choose Python for their analytics workflows. Furthermore, in my experience, teams using Kedro for their machine learning pipelines prefer to use the same tool for data processing and feature engineering code, too.
Can we combine the flexibility and familiarity of Python with the scale and performance of modern SQL? Yes we can! "Ibis is a Python library that provides a lightweight, universal interface for data wrangling." Ibis exposes a Python dataframe API where the same code can execute against over 15 query engines, from local backends like pandas, Polars, and DuckDB to remote databases and distributed computation frameworks like BigQuery, Snowflake, and Spark. Ibis constructs a query plan, or intermediate representation (IR), that it evaluates lazily (i.e. as and when needed) on the execution engine. Of course, if you still want to write parts of your logic in SQL, Ibis has you covered.
Reimagining Python-first production data pipelines
Revisiting the Jaffle Shop
Since dbt represents the industry standard for SQL-first transformation workflows, let's use the Jaffle Shop example to inform the capabilities of a Python-first solution. For those unfamiliar with the Jaffle Shop project, it provides a playground dbt project for testing and demonstration purposes, akin to the Kedro spaceflights project. Take a few minutes to try dbt with DuckDB or watch a brief walkthrough of the same.
If you want to peek at the final solution using Kedro at this point, jump to the "Try it yourself" section.
Creating a custom ibis.Table dataset
Kedro-Ibis integration needs the ability to load and save data using the backends Ibis supports. The data will be represented in memory as an Ibis table, analogous to a (lazy) pandas dataframe. The first step in using Ibis involves connecting to the desired backend; for example, see how to connect to the DuckDB backend. We abstract this step in the dataset configuration. We also maintain a mapping of established connections for reuse—a technique borrowed from existing dataset implementations, like those of .
There's also a need to support different materialisation strategies. Depending on what the user configures, we call either create_table or create_view.
Note: Since this article was originally published, Ibis datasets have been contributed to the official Kedro-Datasets repository. Find the complete dataset implementations on GitHub.
Configuring backends with the OmegaConfigLoader using variable interpolation
Kedro 0.18.10 introduced OmegaConf-native templating in catalog files. In our example:
1# conf/base/catalog_connections.yml
2_duckdb:
3 backend: duckdb
4 # `database` and `threads` are parameters for `ibis.duckdb.connect()`.
5 database: jaffle_shop.duckdb
6 threads: 24
7
8# conf/base/catalog.yml
9raw_customers:
10 type: ibis.TableDataset
11 table_name: raw_customers
12 connection: ${_duckdb}
13 save_args:
14 materialized: table
15
16...Building pipelines
Develop pipelines in the usual way. Here's a node written using Ibis:
1import ibis
2from ibis import _
3
4def process_orders(
5 orders: ibis.Table, payments: ibis.Table, payment_methods: list[str]
6) -> ibis.Table:
7 total_amount_by_payment_method = {}
8 for payment_method in payment_methods:
9 total_amount_by_payment_method[f"{payment_method}_amount"] = ibis.coalesce(
10 payments.amount.sum(where=payments.payment_method == payment_method), 0
11 )
12
13 order_payments = payments.group_by("order_id").aggregate(
14 **total_amount_by_payment_method, total_amount=payments.amount.sum()
15 )
16
17 final = orders.left_join(order_payments, "order_id")[
18 [
19 orders.order_id,
20 orders.customer_id,
21 orders.order_date,
22 orders.status,
23 *[
24 order_payments[f"{payment_method}_amount"]
25 for payment_method in payment_methods
26 ],
27 order_payments.total_amount.name("amount"),
28 ]
29 ]
30 return final
31In comparison, here is the original dbt model:
1{% set payment_methods = ['credit_card', 'coupon', 'bank_transfer', 'gift_card'] %}
2
3with orders as (
4 select * from {{ ref('stg_orders') }}
5),
6
7payments as (
8 select * from {{ ref('stg_payments') }}
9),
10
11order_payments as (
12 select
13 order_id,
14
15 {% for payment_method in payment_methods -%}
16 sum(case when payment_method = '{{ payment_method }}' then amount else 0 end) as {{ payment_method }}_amount,
17 {% endfor -%}
18
19 sum(amount) as total_amount
20
21 from payments
22
23 group by order_id
24
25),
26
27final as (
28
29 select
30 orders.order_id,
31 orders.customer_id,
32 orders.order_date,
33 orders.status,
34
35 {% for payment_method in payment_methods -%}
36
37 order_payments.{{ payment_method }}_amount,
38
39 {% endfor -%}
40
41 order_payments.total_amount as amount
42
43 from orders
44
45 left join order_payments
46 on orders.order_id = order_payments.order_id
47
48)
49
50select * from final
51Note that Ibis solves the parametrisation problem with vanilla Python syntax; on the other hand, the dbt counterpart uses Jinja templating.
Ibis uses deferred execution, pushing code execution to the query engine and only moving required data into memory when necessary. The output below shows how Ibis represents the above node logic. At the run time, Ibis generates SQL instructions from final's intermediate representation (IR), executing it at one time; no intermediate order_payments gets created. Note that the below code requires that the stg_orders and stg_payments datasets be materialised already.
1(kedro-jaffle-shop) deepyaman@Deepyamans-MacBook-Air jaffle-shop % kedro ipython
2ipython --ext kedro.ipython
3Python 3.11.5 (main, Sep 11 2023, 08:31:25) [Clang 14.0.6 ]
4Type 'copyright', 'credits' or 'license' for more information
5IPython 8.18.1 -- An enhanced Interactive Python. Type '?' for help.
6[01/25/24 08:33:22] INFO Resolved project path as: /Users/deepyaman/github/deepyaman/jaffle-shop. __init__.py:146
7 To set a different path, run '%reload_kedro <project_root>'
8[01/25/24 08:33:22] INFO Kedro project Jaffle Shop __init__.py:115
9 INFO Defined global variable 'context', 'session', 'catalog' and 'pipelines' __init__.py:116
10[01/25/24 08:33:23] INFO Registered line magic 'run_viz' __init__.py:122
11
12In [1]: orders = catalog.load("stg_orders")
13[01/25/24 08:36:19] INFO Loading data from stg_orders (TableDataset)... data_catalog.py:482
14
15In [2]: payments = catalog.load("stg_payments")
16[01/25/24 08:36:40] INFO Loading data from stg_payments (TableDataset)... data_catalog.py:482
17
18In [3]: payment_methods = catalog.load("params:payment_methods")
19[01/25/24 08:37:26] INFO Loading data from params:payment_methods (MemoryDataset)... data_catalog.py:482
20
21In [4]: from jaffle_shop.pipelines.data_processing.nodes import process_orders
22
23In [5]: final = process_orders(orders, payments, payment_methods)
24
25In [6]: final
26Out[6]:
27r0 := DatabaseTable: stg_orders
28 order_id int64
29 customer_id int64
30 order_date date
31 status string
32
33r1 := DatabaseTable: stg_payments
34 payment_id int64
35 order_id int64
36 payment_method string
37 amount float64
38
39r2 := Aggregation[r1]
40 metrics:
41 credit_card_amount: Coalesce([Sum(r1.amount, where=r1.payment_method == 'credit_card'), 0])
42 coupon_amount: Coalesce([Sum(r1.amount, where=r1.payment_method == 'coupon'), 0])
43 bank_transfer_amount: Coalesce([Sum(r1.amount, where=r1.payment_method == 'bank_transfer'), 0])
44 gift_card_amount: Coalesce([Sum(r1.amount, where=r1.payment_method == 'gift_card'), 0])
45 total_amount: Sum(r1.amount)
46 by:
47 order_id: r1.order_id
48
49r3 := LeftJoin[r0, r2] r0.order_id == r2.order_id
50
51Selection[r3]
52 selections:
53 order_id: r0.order_id
54 customer_id: r0.customer_id
55 order_date: r0.order_date
56 status: r0.status
57 credit_card_amount: r2.credit_card_amount
58 coupon_amount: r2.coupon_amount
59 bank_transfer_amount: r2.bank_transfer_amount
60 gift_card_amount: r2.gift_card_amount
61 amount: r2.total_amount
62
63In [7]: final.visualize()In the final step, we draw a visual representation of the expression tree. This step requires the graphviz Python library be installed. In practice, we leave these complexities up to Ibis and the underlying engine!

Try it yourself
Clone the deepyaman/jaffle-shop GitHub repository to download the completed Kedro Jaffle Shop project. Run pip install -r requirements.txt from the cloned directory to install the dependencies, including the Ibis DuckDB backend:
1git clone https://github.com/deepyaman/jaffle-shop.git
2cd jaffle-shop
3pip install -r requirements.txtTypically, the source data already resides in a data warehouse. However, for this toy example, the project's data folder includes CSV files necessary to initialise the database: kedro run --pipeline seed
Finally, run the actual pipeline with kedro run.
Voilà! Feel free to confirm that the expected tables and views got created:
1>>> import duckdb
2>>>
3>>> con = duckdb.connect("jaffle_shop.duckdb")
4>>> con.sql("SHOW TABLES")
5┌───────────────┐
6│ name │
7│ varchar │
8├───────────────┤
9│ customers │
10│ orders │
11│ raw_customers │
12│ raw_orders │
13│ raw_payments │
14│ stg_customers │
15│ stg_orders │
16│ stg_payments │
17└───────────────┘
18
19>>> con.sql("SELECT * FROM customers WHERE customer_id = 42")
20┌─────────────┬────────────┬───────────┬─────────────┬───────────────────┬──────────────────┬─────────────────────────┐
21│ customer_id │ first_name │ last_name │ first_order │ most_recent_order │ number_of_orders │ customer_lifetime_value │
22│ int64 │ varchar │ varchar │ date │ date │ int64 │ double │
23├─────────────┼────────────┼───────────┼─────────────┼───────────────────┼──────────────────┼─────────────────────────┤
24│ 42 │ Diana │ S. │ 2018-02-04 │ 2018-03-12 │ 2 │ 27.0 │
25└─────────────┴────────────┴───────────┴─────────────┴───────────────────┴──────────────────┴─────────────────────────┘
26View the pipeline using Kedro-Viz with kedro viz:
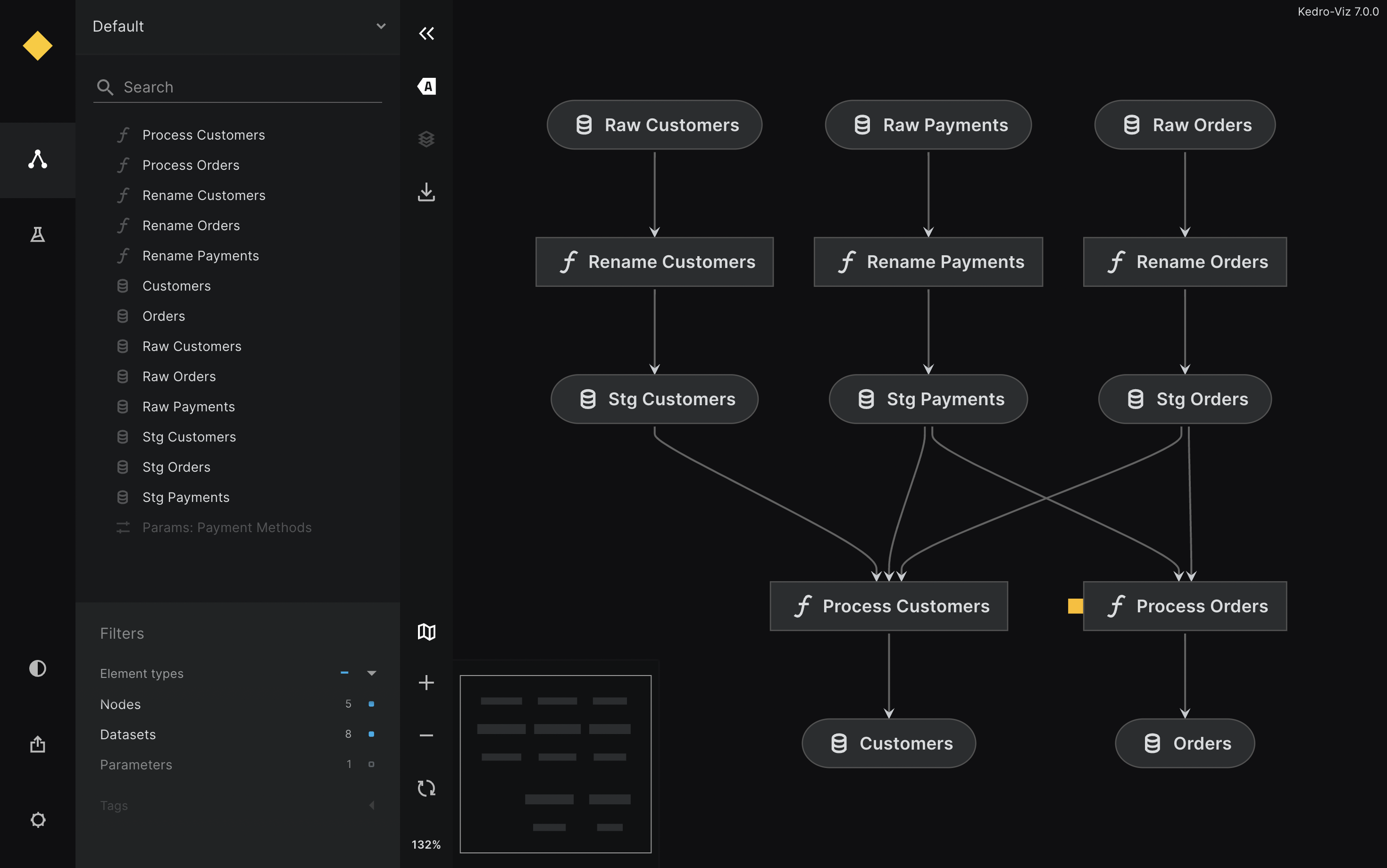
The interactive pipeline visualization is hosted at https://deepyaman.github.io/jaffle-shop/.
But wait... there's more!
Making pipeline productionisation easier alone may justify adopting Ibis into a Kedro workflow, but other situations from my past experience also come to mind.
Have you ever found yourself developing data pipelines against an existing data warehouse, even though you know that the data infrastructure team is currently migrating to a different database solution? You expect to rewrite some amount of your code—unless you use Ibis?
Using Ibis can also help you build truly reusable pipelines. I previously led development of a Kedro-based code asset that provided a suite of reusable pipelines for customer analytics. We decided to use PySpark for data engineering, but many of our users didn't need to use PySpark. One major retailer stored all of their data in Oracle, and they ended up with a suboptimal workflow wherein they extracted data into Spark and did all the work there. Other teams looked at our pipelines for inspiration, but ended up rewriting them for their infrastructure—not our intention in delivering prebuilt pipelines. Last but not least, we spent so much time and effort setting up Spark on locked-down Windows machines, so data scientists could play with the pipelines we provided; being able to run the same logic using DuckDB or pandas locally would have been a godsend!
What's next?
If you're familiar with dbt (or even if you examined the Jaffle Shop project discussed above), you'll notice a key functionality that we didn't implement here: validations. Kedro natively integrates with pytest for unit testing, which plays well for verifying the correctness of transformations developed in Ibis. Kedro also supports data validation through third-party plugins such as kedro-pandera, and I've recently started work on extending pandera to support validating Ibis tables; look for a follow-up post covering that soon.
Ibis supports a subset of DDL operations, which means dbt's incremental and materialized view materialisations currently don't have counterparts yet. Some Ibis backends have explored exposing materialised views. While not explicitly covered above, the ephemeral materialisation equates to Kedro's MemoryDataset.
Finally, dbt offers enhanced deployment functionality, like the ability to detect and deploy only modified models; it's less straightforward to detect such changes with Kedro.
If you have any ideas or feedback about this tutorial or more generally on the pipeline productionisation experience, we would love to hear from you!
This article was updated to fix some links and modify the code on 18th August 2025





