
When training a model in machine learning, the goal is to determine the optimal configuration of attributes such as hyper-parameters, metrics, and training data. The process of identifying the best combinations requires running a lot of experiments and comparing them. As I mentioned in my previous article, experiment tracking is a way to record all the metadata you need to compare machine-learning experiments and recreate them for your project.
What is experiment tracking in Kedro-Viz?
Experiment tracking on Kedro-Viz enables users to select, plot, and compare how multiple metrics change over time, and identify the best-performing ML experiment, with no additional dependencies to manage or infrastructure needed.
The video below demonstrates experiment tracking on Kedro-Viz:
During a project with multiple team members, you could end up with a scenario where the results of your experiments are spread across many machines because people are iterating on their individual computers. This makes the tracking process difficult to manage at a team level, as suggested by this feedback from our users.
"You might train one model locally on your computer. You might train another one in the cloud. Joe might run another pipeline or another experiment. Having all of those experiments in one place as a single source of truth is really powerful.
"If we could write our metrics files to an S3 bucket and then run experiment tracking pointing at that S3 bucket, that simplifies our workflow in many different ways and would be really helpful. And it would make Kedro experiment tracking just as easy, if not easier, than MLFlow for us."
"Can you use an existing database so that we can keep track of runs happening in different places?"
We have found a way to address this pain point and enable you to collaborate more easily. We are excited to announce that we've launched collaborative experiment tracking in Kedro-Viz 6.2.0. The new feature enables a team of users to log their experiments to a shared cloud storage service and view and compare each others' experiments in their own experiment tracking view. This simplifies their workflow, providing a single ‘source of truth’ and encourages multi-user collaboration.
We are releasing this feature in stages across different versions, and the first phase is Kedro-Viz 6.2.0. This version enables users to read experiments of other users that are stored on Amazon S3 or similar storage solutions on other cloud providers, as long as they are supported by fsspec. Future versions of collaborative experiment tracking aim to improve the user experience through automatic reloading and optimisation by caching.
Get started with collaborative experiment tracking
Follow these steps to set up collaborative experiment tracking in Kedro-Viz:
Step 1: Update Kedro-Viz
Ensure you have the latest version of Kedro-Viz (6.2.0 or later).
1pip install kedro-viz --upgradeStep 2: Set up cloud storage
Kedro-Viz uses fsspec to save and read session_store files from a variety of data stores, including local file systems, network file systems, cloud object stores (e.g., Amazon S3, Azure Blob Storage, Google Cloud Storage), and HDFS.
Set up a central cloud storage repository such as a AWS S3 bucket to store all your team's experiments.
Step 3: Configure your Kedro project
Locate the settings.py file in your Kedro project directory and add the following:
1from kedro_viz.integrations.kedro.sqlite_store import SQLiteStore
2from pathlib import Path
3
4SESSION_STORE_CLASS = SQLiteStore
5SESSION_STORE_ARGS = {
6 "path": str(Path(__file__).parents[2] / "data"),
7 "remote_path": "s3://my-bucket-name/path/to/experiments",
8}Step 4: Set up a unique username
Kedro-Viz saves your experiments as SQLite database files on the central cloud storage. To ensure that all users have unique filenames, you need to set up your KEDRO_SQLITE_STORE_USERNAME in the environment variables. By default, Kedro-Viz will take your computer username if this is not specified.
1export KEDRO_SQLITE_STORE_USERNAME ="your_unique__username"Step 5: Configure cloud storage credentials
From Kedro-Viz version 6.2, the only way to set up credentials for accessing your cloud storage is through environment variables, as shown below for Amazon S3 cloud storage.
1export AWS_ACCESS_KEY_ID="your_access_key_id"
2export AWS_SECRET_ACCESS_KEY="your_secret_access_key"
3export AWS_REGION="your_aws_region"In the screenshot below we show an example of the session store and Kedro-Viz output for three team members (Huong, Tynan, and Rashida):
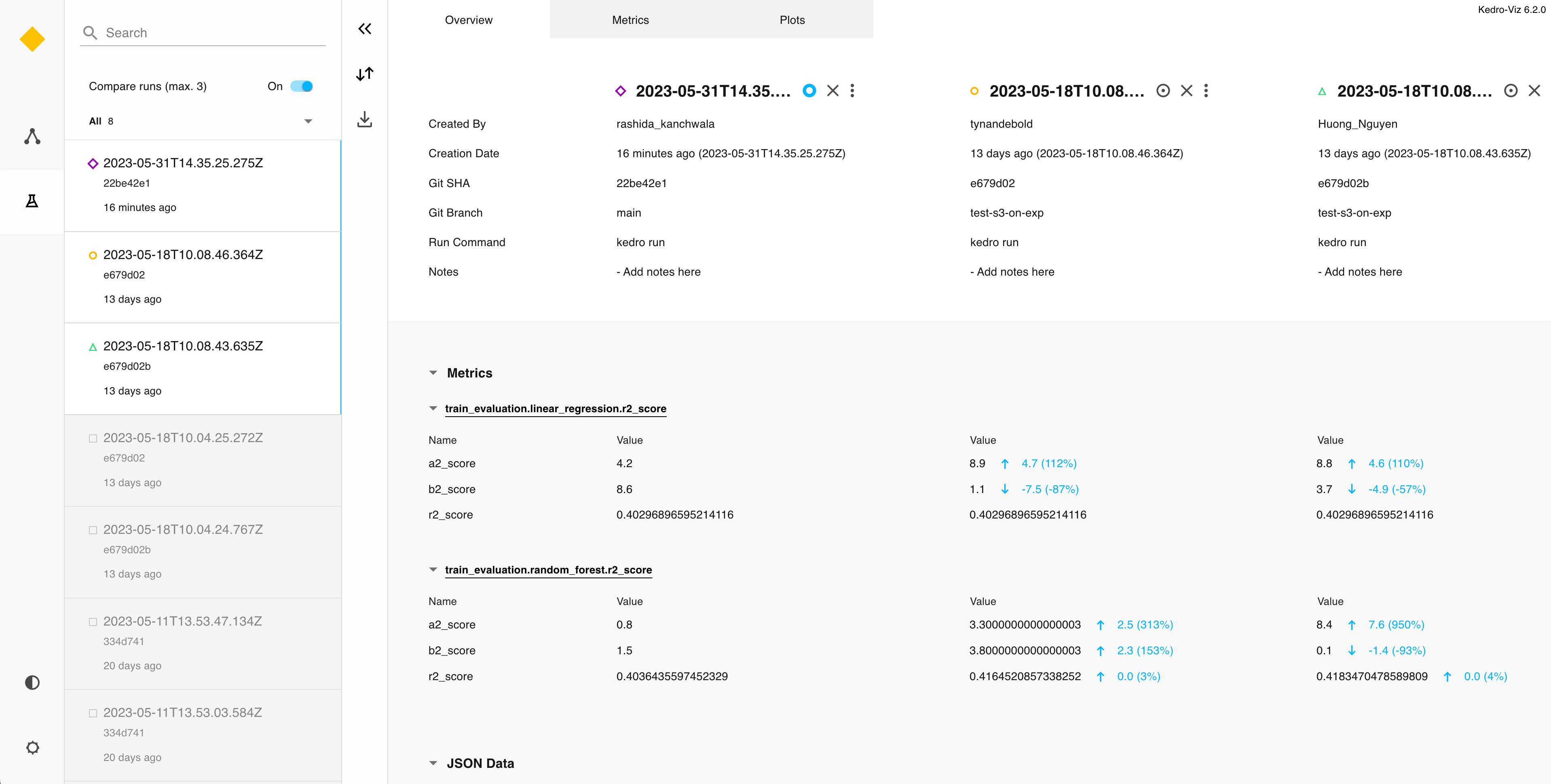
This tutorial offers a very swift run through of the configuration process. For further information, check out the documentation on the experiment tracking feature and keep up-to-date with the latest news about Kedro and Kedro-Viz on our Slack channels.
Many thanks to the Kedro-Viz team especially @Rashida Kanchwala for contributing to this post.
Find out more about Kedro
There are many ways to learn more about Kedro:
Join our Slack organisation to reach out to us directly if you’ve a question or want to stay up to date with news. There's an archive of past conversations on Slack too.
Read our documentation or take a look at the Kedro source code on GitHub.
Check out our video course on YouTube.
Recently on the Kedro blog
Recently published on the Kedro blog:
We’re always looking for collaborators to write about their experiences using Kedro. Get in touch with us on our Slack workspace to tell us your story!





